Record Type |
BIB |
Bytes |
ALL: 008/38 |
Input standards |
ALL: Required if applicable. One-character code. Default: 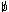 |
Definition |
|
| ALL |
Whether bibliographic information was modified for entry into machine-readable form. |
Guidelines |
|
| Transcribing printed copy |
Use the following guidelines when transcribing LC or NLM printed copy. If more than one MRec code applies, use the codes according to the following order of preference: s, d, x, r, o. |
| |
| |
Leave the default value blank if transcribing LC or NLM cataloging exactly as found on LC or NLM printed copy. Modernization of a form of heading or of subject terminology does not require an MRec code. If the printed copy has incidental non-Latin characters, unusual mathematical symbols or other special characters not included in the OCLC character set, follow these guidelines:
- Consider the copy to have incidental non-Latin or special characters if these characters occur in one field (or a portion of one field) among fields 245-264 or 4xx.
- Romanize non-Latin characters and describe special symbols with a word or phrase.
- Enclose the romanized or modified characters within brackets. (Romanization may apply to a single letter, to a single word, to several words or to the entire field.) Since the brackets identify modified characters, you need not indicate modification. Leave MRec coded blank.
- If two or more fields among fields 245-264 or 4xx require romanization, see code r.
|
|
| |
|
| |
| d |
If a pre-AACR2 record (e.g., retrospective cataloging being converted to machine-readable form), has a "dashed-on" entry, do not enter the dashed-on information. Enter your OCLC symbol in field 040 subfield ǂd and use code d. Create a separate bibliographic record describing the dashed-on item. |
|
| |
| r |
If LC or NLM cataloging is in a non-Latin alphabet, enter the record in romanized form. LC prints non-Latin cataloging for Chinese, Japanese, Korean, Arabic, Persian and the Hebraic script. In such cases, use code r and enter your OCLC symbol in field 040 subfield ǂd. |
|
| |
| o |
If LC or NLM cataloging is itself romanized, enter the record in romanized form. LC romanizes its printed cataloging for non-Latin alphabets, except Chinese, Japanese, Korean, Arabic, Persian and the Hebraic script. In such cases, use code o but do not enter your OCLC symbol in field 040 subfield ǂd since the machine-readable record matches the printed record. |
|
| Original cataloging |
Use the following guidelines if you are inputting original cataloging and other non-LC or non-NLM cataloging. If more than one MRec code applies, use codes according to the following order of preference: s, r, o. |
| |
| |
Not modified If the original bibliographic data has incidental non-Latin characters, unusual mathematical symbols or other special characters not included in the character set, follow these guidelines:
- Consider the data to have incidental non-Latin or special characters if these characters occur in one field (or a portion of one field) among fields 245-264 or 4xx.
- Romanize non-Latin characters and describe special symbols using a word or phrase.
- Enclose the romanized or modified characters within brackets. Romanization may apply to a single letter, to a single word, to several words or to the entire field. Since the brackets identify modified characters, no additional indication of modification is necessary, leave MRec coded blank.
- If two or more fields among fields 245-264 or 4xx require romanization. See codes r and o.
|
|
| |
| o |
If the original bibliographic data are in a non-Latin alphabet, enter the record in romanized form. If LC printed cataloging for the item would also be romanized, use code o. LC romanizes its printed cataloging for non-Latin alphabets, except Chinese, Japanese, Korean, Arabic, Persian and Hebraic script. |
|
| |
| r |
If the original bibliographic data are in a non-Latin alphabet, enter the record in romanized form. If LC printed cataloging for the item would also be in a non-Latin alphabet, use code r. LC prints non-Latin cataloging for Chinese, Japanese, Korean, Arabic, Persian and Hebraic script. |
|
| |
|
Codes |
|
| |
|
Not modified |
|
| |
| d |
Dashed-on information omitted. Pre-AACR2 only. |
|
| |
| o |
Completely romanized/printed cards romanized |
|
| |
| r |
Completely romanized/printed cards in script |
|
| |
|
| |
| u |
Unknown. Obsolete. Do not use. |
|
| |
|
| |
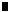 |
No attempt to code |
|
Indexing |
This fixed field element is not indexed. |
MARC 21 |
For more information, including content designator history, see MARC 21 Format for Bibliographic Data, 008/38 (All Materials). |