Library Linked Data in the Cloud
OCLC's Experiments with New Models of Resource Description

Authors
Jean Godby, Ph.D.
Senior Research Scientist
Shenghui Wang, Ph.D.
Research Scientist
Jeff Mixter
Sr. Software Engineer
Chapter 1: Library Standards and the Semantic Web
- 1.1 The Web of Documents and the Semantic Web
- 1.1.1 Records and Graphs
- 1.1.2 The Linked Data Cloud
- 1.2 OCLC’s Experiments in Context
- 1.3 A Technical Introduction
- 1.4 Chapter Summary
1.1 The Web of Documents and the Semantic Web
“Most of the Web’s content today is designed for humans to read, not for computer programs to manipulate meaningfully. Computers can adeptly parse Web pages for layout and routine processing—here a header, there a link to another page—but in general, computers have no reliable way to process the semantics: this is the home page of the Hartman and Strauss Physio Clinic, this link goes to Dr. Hartman’s curriculum vitae.
The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users. …[It] is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation. The first steps in weaving the Semantic Web into the structure of the existing Web are already under way. In the near future, these developments will usher in significant new functionality as machines become much better able to process and ‘understand’ the data that they merely display at present.” (Berners-Lee, Hendler, and Lasilla 2001)
Readers in 2001 might have read this account of the Semantic Web as science fiction, especially the details of how it would be put to use. In the same passage, the authors describe a hypothetical scenario featuring a ringing phone that lowers the volume of nearby devices so its human owner can take an urgent call from a physician, followed up with the complex logistics of arranging appointments and prescriptions for an aging parent. These details are managed automatically by robots roaming across a smarter Web to collect names, addresses, and ratings of nearby health-care providers and insurance companies.
Fourteen years later, this scenario might be interpreted as an edge-case application of the Semantic Web, but is not especially far-fetched. It depends on the transformation of the Web from a collection of documents that are displayed to a human reader to a network of structured data that is associated with real things in the world, such as patients, physicians, pharmacies, and schedules. Thus, in some limited sense, structured data can be understood and acted upon by algorithmic processes that do something useful. Less dramatic applications of the Semantic Web data architecture are now part of everyday experience. They offer invisible assistance to a traveler wishing to locate highly rated farm-to-table restaurants in a strange city, a shopper wanting to buy a gallon of Benjamin Moore’s ‘Guilford Green’ from the closest paint store, and a student searching Google for the basic facts about William Henry Harrison, the ninth President of the United States. A plausible addition to this list is an improved Web experience that would make libraries and their collections more prominent and accessible to the information-seeking public. This book is a progress report on that goal, focusing on OCLC’s experiments with metadata managed by libraries using the conventions of linked data, the latest convention for realizing the promise of the Semantic Web.
1.1.1 Records and Graphs
A more concrete discussion can begin with picture of a document that should be familiar to librarians, publishers, and information seekers, and its reformulation as a network of structured data. Figure 1.1 shows a simplified view of the ‘before’ and ‘after’ formats for a description of a paperback edition of Shakespeare’s Hamlet published by Penguin Books in 1994. Above the blue, book-shaped icon near the bottom of the figure is a record representing the work, which lists its author, title, publisher, publication date, ISBN, and page count. Records in this format can be extracted from nearly all published standards for bibliographic description and are ubiquitous in library catalogs, OCLC’s WorldCat catalog data, and bookseller websites such as Amazon.com. Extending upward from the record along multicolored paths, the same information is encoded as a labeled graph that distills the essential meaning of the document. Though the output might appear stilted to a human reader, the information captured in the graph can be assembled into atomic statements such as ‘Penguin Books is the name of an Organization,’ ‘Penguin Books is the publisher of Hamlet,’ ‘William Shakespeare is the name of a person,’ ‘William Shakespeare is the author of Hamlet,’ ‘An edition of Hamlet has the publication date 1994,’ ‘Penguin Books is located in a place,’ ‘New York is the name of a place,’ and so on. Each statement associates nouns—or ‘entities’—such as ‘William Shakespeare’ or ‘Hamlet’ with a verb or verb phrase of some kind–or ‘relationships’—such as ‘is the author of,’ to create what computer scientists call an ‘entity-relationship’ graph.
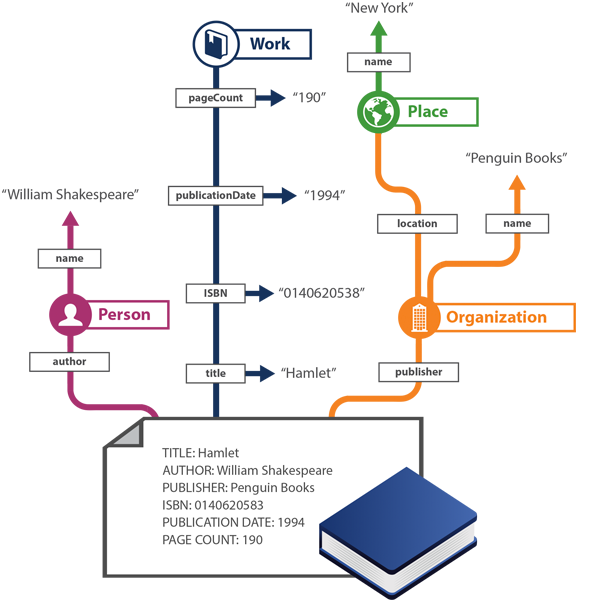
For the past eight years, OCLC researchers have been working with library standards communities to define entity-relationship models for the description of resources managed by libraries and implement them on a large scale in OCLC’s publicly accessible databases. Newcomers to this project often ask whether the result is a new view or an enhancement of existing formats, or a new model altogether; and, more importantly, why the difference in representation matters.
We can formulate a rough draft of an answer to these questions by taking a closer look at Figure 1.1. A human reader can infer from the description at the bottom of the image that William Shakespeare is a person who wrote something named Hamlet, which was published in 1994 by a company named Penguin Books. The reader might have learned in a literature class or an encyclopedia article that William Shakespeare was a man who lived in England in the 1500s. The same authoritative sources would also enable a reader to learn that Hamlet is a play originally written in verse in a form of English that contemporary readers consider archaic, and is one of Shakespeare’s most famous works. Readers who wish to obtain a copy of this edition of Hamlet might make an intelligent guess that if it is a typical product from Penguin Books, it is a small, inexpensive paperback volume that can be obtained from a library or bookseller by entering the ISBN into an order form, typically through a Web interface. Thus the human reader can assign an actionable interpretation to the description at the bottom of the image. But a machine cannot. The largest obstacle is that such records consist primarily of text that must be parsed and interpreted with the help of real-world knowledge, a task that outstrips the capabilities of the current generation of natural language processing software.
To compensate, data scientists have been designing entity-relationship models since the 1970s. By reducing the complexity of natural language to manageable sets of nouns and verbs that are well-defined and unambiguous, sentence-like statements can be interpreted without the need for computationally expensive and error-prone process operating literally on human-readable text. What emerges from this exercise is a formal model of a restricted domain from which a network of self-contained statements with a machine-understandable semantics can be generated. In the small domain defined by Figure 1.1, for example, William Shakespeare would be mentioned in other statements about authorship because he created many works in addition to Hamlet. So would the city of New York, because it is significant for plenty of other reasons important to librarianship besides its location as the corporate headquarters for Penguin Books. The statements that can be generated from the graph shown in Figure 1.1 conform to semantically realistic co-occurrence rules, stipulating that objects are located in a place, or that books have publication dates but organizations do not.
Linked data can be understood as an entity-relationship model with additional requirements. The seminal statement of linked data principles (Berners-Lee 2006), which we discuss in more technical detail in the next section of this chapter, defines linked data as a network of structured statements, or a ‘dataset,’ expressed using a published vocabulary and a model that identifies entities as things that ordinary people talk about. Put simply, linked data is about things that link to other things. Linked data principles also stipulate the need for authoritative resources about entities—which, for example, associate the sixteenth-century English playwright named ‘William Shakespeare’ to persistent Web-accessible links that resolve to machine-understandable identifying information. Encyclopedias and other trusted references satisfy this need in the web of documents, but only humans can read them. The Semantic Web representation can be interpreted as a computational model of those things that humans remember and know to be true. In other words, Semantic Web conventions for describing entities have the effect of promoting a string in a text to a ‘thing’ in the world. In this formulation, the ‘William Shakespeare’ mentioned in the description of Hamlet shown in Figure 1.1 is correctly identified as the name of the English literary icon and not a dog or a rock band, and represents knowledge about the author of Hamlet that endures beyond a single mention in an individual document.
But as Tim Berners-Lee and his coauthors said in the passage quoted at the beginning of this chapter, the Semantic Web is not separate from the web of documents, but an extension of it. Evidence of their coexistence is shown in Figure 1.2, which is a screen capture of a search on Google for Hamlet issued in early 2014.
On the left is a ranked list of documents, produced by matching text strings in the user’s query using updated versions of decades-old information-retrieval algorithms that encode no understanding of the real world behind the text. On the right is a display built from the Knowledge Graph, announced by Google in 2012. Sometimes called the ‘Knowledge Card,’ the display is fundamentally different from the document list because it is about Hamlet the real-world entity, not its text-string name. It is built by mining facts from data sources such as Freebase (Google 2015), Wikipedia, and the CIA World Factbook (CIA 2015), and reducing them to a composite description featuring only the most reliable information that can be algorithmically discovered. As of 2012, Google had generated Knowledge Cards for 500 million entities, which are populated with 3.5 billion statements extracted from the Knowledge Graph (Google 2012). An experimental upgrade to the Knowledge Graph assembles a network of entities and relationships from a larger variety of inputs and uses machine-learning algorithms to make quality assessments, remove duplicates, merge statements about a given entity from different sources, and draw inferences that can be translated into more machine-processable statements (Dong et al. 2014). Thus the data stores that make up the Semantic Web continue to grow in size and accuracy.
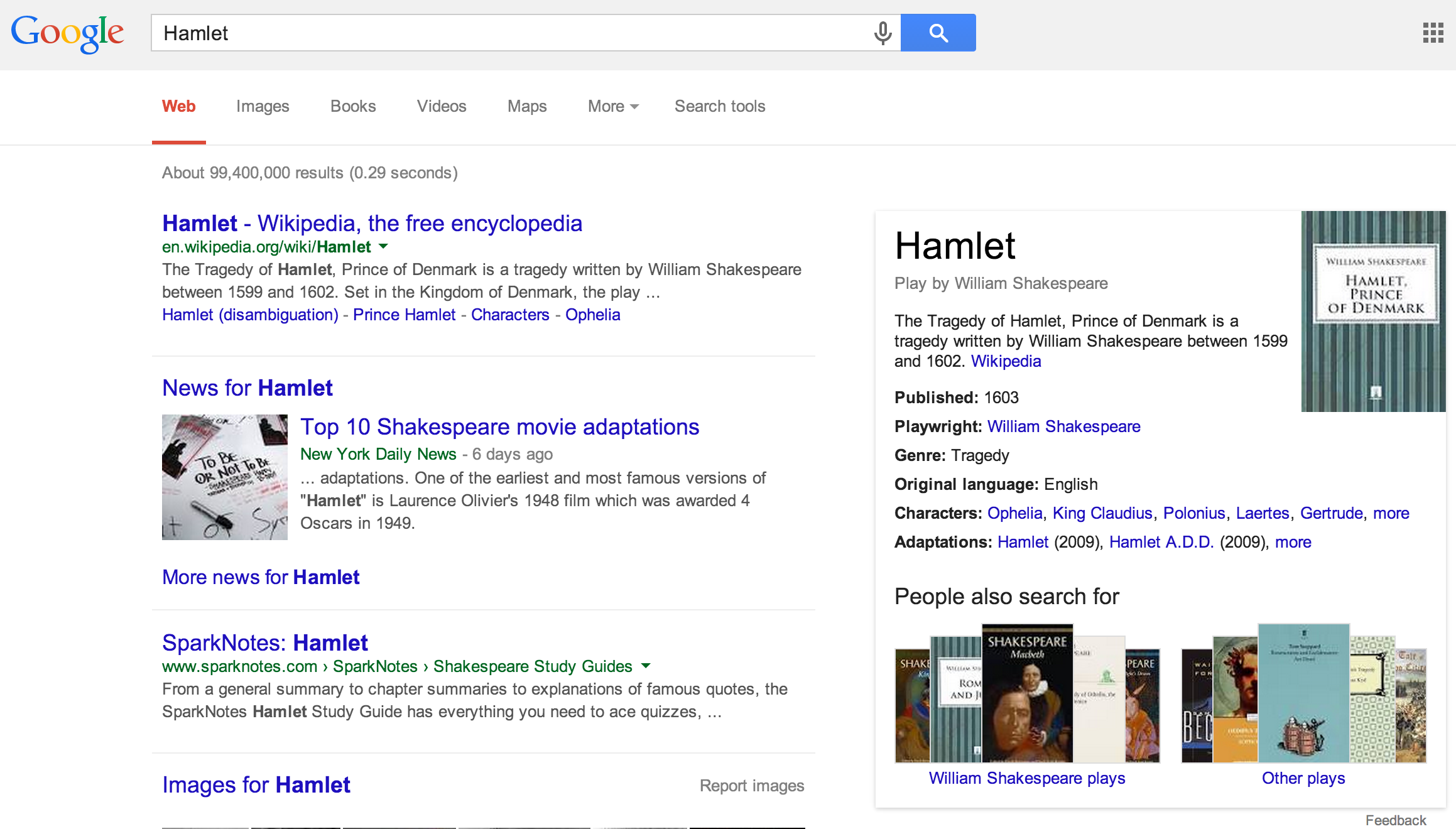
Semantic Web outputs such as the Knowledge Graph are important for three reasons. First, the structured display of the Knowledge Card is easy for users to comprehend and navigate. For example, in the process of building Figure 1.1, algorithms have already determined that the entity in question is Shakespeare’s play. Likewise, the Knowledge Card displayed in response to a student’s request for information about William Henry Harrison, mentioned earlier, is about the ninth president of the United States. In both cases, information seekers can learn more simply by clicking on the links in the card because the real-world reference has already been resolved. The document list, however, requires the user to evaluate the relevance, veracity, trustworthiness of each item.
Second, a real-world entity, unlike a list of documents, is an object that may be described in multiple data sources or knowledge stores. If the entity is uniquely and publicly identified, these data sources can be merged more easily. This is the key to the smooth operation of the applications of the Semantic Web mentioned in the opening paragraphs of this book: restaurants merged with reviews; a particular kind of paint merged with information about that stores that carry it; and even the complex interactions among physicians, patients, drugs and providers managed by robots that could have been read as science fiction a decade and a half ago.
Finally, entities are natural collection points on the Web for inbound and outbound links involving other entities. William Shakespeare the playwright will attract many links because a globally important entity is mentioned in many resources. In return, globally important entities, and the entities most closely related to them, will be more prominent and thus easier to find in a Web search. This is the same logic that produces ordered lists in the web of documents because those that accumulate the most links are ranked near the top. Thus if William Shakespeare is defined as an entity in the Semantic Web, the creative works by and about him should be more prominent in Web searches, as should the libraries, archives, museums, and booksellers that make these resources available to information seekers. In the domain that is the subject of this book, this is the most useful task that the Semantic Web can accomplish.
Achieving these results in a web of documents has proven intractable, however, because natural language is ambiguous and infinitely variable. As a consequence, the things that people want to know about are too often buried in a sea of text.
1.1.2 The Linked Data Cloud
In the past five years, the collection of structured datasets conforming to linked data conventions has grown and now represents contributions by many communities of practice, including science, medicine, scholarship, multimedia, government, publishing, and librarianship. In visual terms, the iconic image of the ‘Linked Open Data Cloud’ maintained by Cyganiac and Jensch (2014) and partially reproduced in Figure 1.3 has become more dense and interconnected. At the center is DBpedia (2015), the structured dataset extracted from Wikipedia, but many other secondary hubs are also visible. For example, GeoNames GN (2014) contains names, images, and geospatial coordinates for 8 million geographic features and 2.5 million populated places; MusicBrainz (MB 2015) is a community-maintained encyclopedia of music; and CiteSeer (PSU 2014) is a digital library of scientific literature. Linked data resources originating from librarians and publishers are shown as green circles in Figure 1.3, which make up about 15% of the total. Among them are some of the most frequently cited datasets in the linked data cloud and represent several projects discussed in this book, including the Library of Congress Subject Headings, the Virtual International Authority File, and WorldCat, as well as projects sponsored by several European libraries.

In effect, the evolution from the web of documents to the Web of Data defines a new landscape and redefines what it means to publish on the Web. ‘What the Web wants,’ according to Wallis (2013), is not another database of documents, but large datasets that describe things in the world with authority. They are designed with a familiar structure, a web of links, and entity identifiers that can be mined by third-party data consumers who provide complementary value.
It is common knowledge that most searches for information start not in the library nor even in a Web-accessible library catalog, but elsewhere on the Internet. OCLC’s Perceptions of Libraries reports document this change in behavior. In 2003, just five years after the appearance of Google, seventy-five percent of college students reported using the Internet more than the library; in 2010, Internet usage had increased among all age groups and was measurable through several kinds of mobile devices (de Rosa et al. 2010). Unfortunately, the contents of library collections are not visible enough on the Web. Fons (2013) argues that libraries perform four functions—acquiring, describing, preserving, and making resources available to patrons—and that current library standards do the first three reasonably well. But reaching users means doing a better job of moving more and richer datasets into the linked data cloud—i.e., exposing library collections on the Web by defining and publishing structured data that describes the important entities and relationships involved in the description of the world’s most influential creative works.
The practical goal of the work reported in this book is to define the first draft of an entity-relationship model of creative works and transactions in the library community that impact them, expressing the model in the linked data paradigm. The first outcome is a machine-processable set of statements corresponding to those mentioned at the beginning of this chapter: a Person authors a Work; a Work is ‘about’ a Concept; a Work is transformed into an Object by a Publisher; a Publisher is an Organization; a Work, Person, Object, or Organization is located in a Place. The model is realized by mining the data stores maintained at OCLC, focusing on the bibliographic descriptions represented in WorldCat, the aggregated catalog of the world’s libraries that connects users to hundreds of million books, journals, e-resources, and multimedia objects. The results are published in Schema.org, the vocabulary used by the world’s largest search engines to index documents and create structured representations.
In this way, we can satisfy the requirements for the Web of Data by mining large datasets for knowledge about important things in the world and transforming the output to a format that can be understood beyond the library community. By doing so, we are exercising some of the core values of the library profession, which places a premium on collaboration and openness. In return, the Web of Data benefits from the collective expertise and authority of over a hundred years of librarianship.
1.2 OCLC’s Experiments in Context
This section places the concepts we have just described in a larger historical context and sets the stage for a more formal discussion of OCLC’s experiments with new models of resource description. Though we will have to retrace a few steps, our goal is to drive the exposition forward with interconnected story lines about the evolution of Web and library standards. But this survey is necessarily selective. For more detail about the Web protocols described here, see (Heath and Bizer 2011). Recent histories of library standards for resource description are recounted in Ford (2012); Fons, Penka, and Wallis (2012), and Kroeger (2013).
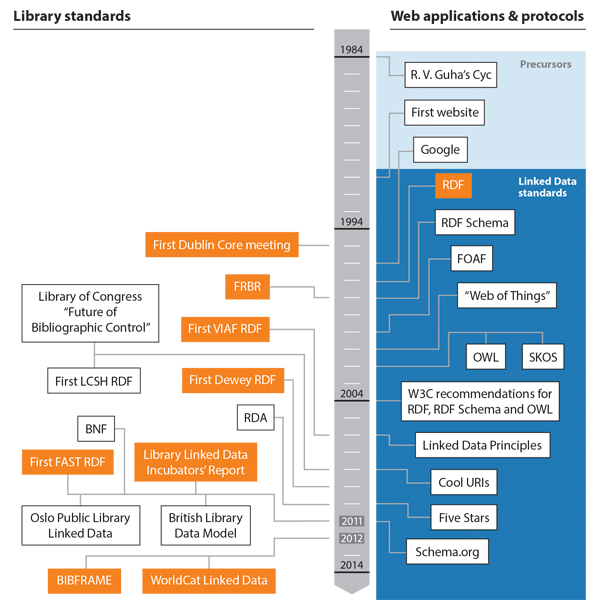
Highlights that are discussed in this book are depicted in the timeline shown in Figure 1.4. The right side shows key milestones in the development of Web standards, protocols, and applications, while the left side shows some of the most important reactions by the library standards community. The orange blocks represent the involvement of OCLC, either as managers of high-profile projects, or as leaders in community-driven initiatives. As Figure 1.4 shows, our thumbnail history is divided into three stages: precursors, protocol and standards development, and applications.
1.2.1 Web Standards for Delivering Documents and Things
In 1991, Tim Berners-Lee announced the birth of the World Wide Web with a document that defined his invention as “a wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents” (WWW 1991). Hypermedia, which includes images and sound, was defined as an extension of hypertext, a term famously coined by Ted Nelson 17 years earlier in a self-published book (Nelson 1974). In 1994, Berners-Lee founded the World Wide Web Consortium, or the W3C, an international body for developing standards and engaging in outreach and education. An early priority was the definition of standards and protocols for the structure and semantics of hyperlinks. The URL, or Uniform Resource Locator, is the character string displayed in the address bar of a browser when a document is accessed. The ‘URL’ concept was quickly absorbed into popular culture, but the broader taxonomy defined two other kinds of links. The URN, or Uniform Resource Name, identified the name of a Web resource independently of its location. The URI, or Uniform Resource Identifier, was the parent term for URLs and URNs that would become the term of choice for referring to the links in linked data (URI-PIG 2001).
Despite the intuitive appeal of the hypermedia browsing experience, Web standards experts realized that knowledge discovery in such an environment is problematic and could be improved by the widespread availability of semantically rich structured data. Thus the Semantic Web was born, and proposals for describing Web-friendly structured data were soon published, many of which matured into formal standards. The Resource Description Framework, or RDF, would become the language of choice for linked data and was already the topic of discussion by multiple and overlapping standards committees in the late 1990s. This discussion produced three important results. First to appear was the ‘Resource Description and Framework Model and Syntax’ specification (Brickley and Guha 2014), introduced in a progress report in 1997 (Miller and Schloss 1997). The initial draft of the corresponding RDF Schema (Brickley and Guha 2014) was published in 1998 (Brickley, Guha, and Layman 1998). Finally, the Web Ontology Language, or OWL (W3C-OWL 2012), was defined as an expanded formal semantics for RDF and was published as a W3C working draft in 2002 (Dean et al. 2002). All three standards first advanced to W3C recommendation status in 2004 (Klyne and Carroll 2004; Brickley and Guha 2004; Dean and Schreiber 2004).
Metalanguages for describing ontologies in RDF were published only slightly later, two of which are especially important for the models discussed in this book. The Simple Knowledge Organization Scheme, or SKOS (Miles and Bechhofer 2009b), is a lightweight vocabulary for expressing thesauri and other structured vocabularies as RDF, which achieved W3C recommendation status in 2009. The ‘Friend of a Friend,’ or FOAF ontology (Brickley and Miller 2014), was designed for describing social networks and was first introduced in 2000, several years before linked data principles were published. Though FOAF is not a W3C standard, its importance was recognized by Tim Berners-Lee in 2007, who claimed that “I express my network in a FOAF file, and that is a start of the revolution” (Berners-Lee 2007).
In the next phase, Web standards experts recognized the need to refer not only to a web of hyperlinked documents, but also to a web of ‘things’ (Berners-Lee 2001). In 2006, Tim Berners-Lee issued the design principles for linked data, stating that “The Semantic Web isn’t just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data” (Berners-Lee 2006). To realize this vision, Berners-Lee proposed that URIs should refer to things in the world; and that when the URIs are resolved, useful information about these things, including other URIs, should be supplied. As he admits, this is a recommendation for applying the design of Web-accessible thesauri to resources about the people, organizations, places, and concepts that populate the larger universe of Web documents. For example, the user who searches for ‘astronomy’ in the online version of Wordnet (PU 2013) retrieves a dedicated page with the unique identifier http://wordnet-online.freedicts.com/definition?word=astronomy, a definition, and a set of links to broader and narrower terms, such as ‘physics,’ ‘physical science,’ ‘astrometry,’ and ‘solar physics.’ According to Berners-Lee, a linked data resource about William Shakespeare should offer the same kind of information. To accomplish this goal, ” Sauermann and Cyganiac (2007) argue in the document “Cool URIs for the Semantic Web” Sauermann and Cyganiac (2007) that a ‘real-world object—or, more commonly, a ‘thing’—is different from a Web-accessible document about it, and define Web protocols to encode the distinction.

In 2010, Berners-Lee published an update to his 2006 document with what would become a widely reproduced and iconic image: the coffee cup with five stars, shown in Figure 1.5. The cup, and the accompanying explanation, can be interpreted as a graduated list of technical and accessibility requirements for realizing the full linked data vision. From a technical perspective, the goal is a set of globally unique URIs to real-world things, related to one another through relationships expressed in a domain model, which is coded in RDF using published vocabularies that can be consumed by third parties. Independent of these requirements is the declaration of a professional ethic promoting the value of machine-readable data in a non-proprietary format that is openly accessible on the Web. Together, the five stars imply that data stores of the highest quality are fully open as well as linked, and represent a checklist that is routinely applied to linked data projects, including OCLC’s.
By 2011, the design principles of linked data were established well enough that Google, Yahoo, Bing, and Yandex could announce the publication of Schema.org, the comprehensive vocabulary that these search engines would use for indexing Web pages and creating structured data, such as the Google Knowledge Graphs we have already mentioned. Though the appearance of Schema.org was perceived as abrupt at the time, the groundwork had prepared through decades of research in knowledge engineering. The primary author was R.V. Guha, who based it on the comprehensive ontology Cyc, which was first introduced in the 1970s (Lenant and Guha 1989). During the formative years of the Semantic Web, Guha also worked behind the scenes to improve the most important standards, particularly the RDF Schema (Brickley and Guha 2014).
Looking back on his experience in 2014, Guha observed that despite the growing sophistication of the Semantic Web standards, fewer than 1,000 sites were using these standards to produce structured data even as late as 2004. Still missing was a value proposition aimed at webmasters that promises greater visibility and more easily navigable displays to those who make structured data available to search engines. To paraphrase the text on a slide from a recent presentation, Schema.org permits simple things to be simple and complex things to be possible (Guha 2014). Schema.org markup is now being published by major sites in a variety of sectors, including news, e-commerce, sports, medicine, music, real estate, and employment. The vocabulary is managed through direct engagement with communities of practice and moderated discussion on W3C lists.
1.2.2 The Library Community Responds
Largely in response to the evolution of the Web in the 1990s as a compelling platform for free access to high-quality information, library standards were also undergoing major change. In 1995, members of the library and Internet standards communities assembled for the inaugural Dublin Core meeting, less than a year after the first World Wide Web conference. They argued that a lightweight version of librarians’ descriptive standards should be applied to Web documents to facilitate discovery (Weibel et al. 1995). This focus on description evolved into an interest in structured data and early leadership roles by members of the library community in the development of RDF. For example, Eric Miller, who worked as a research scientist at OCLC on the initial RDF specifications, later served as the Semantic Web Activity Lead for the World Wide Web Consortium.
In the broader library community, the Web was recognized as a disruptive technology that could either help libraries or threaten them with obsolescence. In a survey of the new landscape, Dempsey et al. (2005) explored the implications for the discovery and description of library resources. Since, as the authors pointed out, “…for many users, Google and other search engines are increasingly becoming the first and last search result,” it would be necessary to manage metadata encoded in library-community standards alongside a much greater diversity of structured and semi-structured text. In addition, the key references maintained by the library community—such as vocabularies, authority files, and mappings among metadata standards—would have to be recast in Web-friendly formats to leverage their value in an environment that integrates libraries with the Internet at large. If these challenges cannot be met, the authors argued, the most valuable library resources would be lost in a sea of other options.
A sense of urgency was also conveyed in the report published in 2008 by the Library of Congress, On the Record, which permeated all aspects of librarianship, but was especially acute in the domain of data standards and technical infrastructure. By then, it was widely recognized that MARC (or Machine-Readable Cataloging) and the other first-generation standards that had brought libraries into the computer age starting in the 1960s were nearing the end of their useful lives. The authors of the report concluded that “the World Wide Web is both our technology platform and the appropriate platform for the delivery of our standards” and that “people are not the only users of the data we produce in the name of bibliographic control, but so too are machine applications that interact with those data in a variety of ways” (LC 2008b).
After the publication of On the Record, the Library of Congress formed the Bibliographic Framework Transition Initiative, a working group that recommended the use of entity-relationship models such Functional Requirements for Bibliographic Description, or FRBR (IFLA-SG 1998), and Resource Description and Access, or RDA (2010). The same group sponsored the development of BIBFRAME (LC 2014b), a linked-data compatible model of bibliographic description that was positioned as a replacement for MARC and would be published as an early draft in 2012. During the same period, library standards experts developed RDF-encoded abstract models (DCMI 2007), created repositories of Web-accessible ontologies and vocabularies such as the Open Metadata Registry (OMR 2014), and built Web-friendly models for nontraditional resources managed by libraries and other cultural heritage institutions—for example, the Europeana Data Model (Europeana 2014). Much of this activity can be interpreted as anticipatory, but as soon as the Web protocols for linked data were mature enough to support the publication of large data stores, many important library authority files were redesigned for the new architecture, including the Library of the Congress Subject Headings, or LCSH (Summers et al. 2008); the Virtual International Authority File, or VIAF (2014); the Faceted Application of Subject Terms, or FAST (OCLC 2011b); and the top-level hierarchies in the Dewey Decimal Classification (Panzer and Zeng 2009).
1.2.3 Linked Data in WorldCat
The projects described in this book emerged in 2011 and 2012, two especially productive years. In 2011, the W3C-sponsored Library Linked Data Incubator Group published a consensus statement (Baker et al. 2011). Among the Incubators were many of the leaders of the projects reported in the publications cited above, including OCLC’s Jeff Young, the chief architect of OCLC’s published linked data, and Michael Panzer, Editor in Chief of the Dewey Decimal Classification.
The Incubators’ statement is grounded in two critical observations. First, they argue that “Linked data builds on the defining feature of the Web: browsable links (URIs) spanning a seamless information space.” They also recognize that “Linked data is not about creating a different Web, but rather about enhancing the Web through the addition of structured data.” The report also lists the arguments for the production and consumption of linked data by libraries, describes the status of the linked data projects in the library community as of 2011, and identifies obstacles to progress. In essence, the Incubators argued that linked data is consistent with the core values of librarianship that emphasize the collaborative creation of metadata and the open sharing of resources. The new architecture simply sets a higher standard for acting on these values. Linked data design principles stipulate that resource descriptions contain globally unique identifiers and be capable of machine interpretation outside their original community of practice. The Incubators’ report points out that these requirements were first demonstrated to be feasible in the conversion of library authority files. But bibliographic description is a much larger challenge because of the larger scope of the standards; MARC alone can express thousands of concepts, which are encoded primarily as human-readable text (Smith-Yoshimura et al. 2010). Karen Coyle, an Incubator, prescribes a ladder of success from text to machine-processable data (Coyle 2012) that can be interpreted as a set of steps for upgrading bibliographic metadata to five-star linked data, following Tim Berners-Lee’s 2010 recommendations.
While the Incubators’ report was being prepared, there were other major developments. First, the British Library published a data model, accompanied by a dataset that described all 2.5 million resources in the British National Bibliography (Hodson et al. 2012), producing the largest and most sophisticated linked data implementation of library bibliographic description to date. Second, the entire catalog of the Oslo Public Library was published as linked data (Rekkavik 2014). Finally, Schema.org was published. By then, OCLC’s research team was engaged in the task of creating linked data for the entire collection of WorldCat catalog data. Since our initial evaluation of Schema.org consisted of relabeling some of the descriptions available from the British Library dataset, which we describe in more detail in Chapter 3, we concluded that Schema.org is rich enough to accomplish the same goals and has the considerable added benefit of being consumable by the world’s major search engines.
In 2012, an experimental draft of a linked data model for bibliographic description derived from Schema.org was published as RDFa markup, an RDF syntax that is compatible with HTML (Herman, Adida, and Sporny 2013), on approximately 300,000,000 HTML-encoded MARC records accessible from WorldCat.org. These descriptions contained URIs linking to RDF datasets that represent the Dewey Decimal Classification, the Library of Congress Subject Headings, the Library of Congress Name Authority File, VIAF, and FAST. By orders of magnitude, this was the largest set of linked library bibliographic data expressed “…in the form the Web wants,” in terms of scale, a familiar structure, a network of links, and entity identifiers. The significance of this achievement was highlighted in a press release (OCLC 2012): “Adding linked data to WorldCat records makes those records more useful—especially to search engines, developers, and services on the wider Web, beyond the library community. This will make it easier for search engines to connect non-library organizations to library data.” In 2014, these descriptions were significantly enhanced by the addition of URIs from WorldCat Works (oclc2014˙works ), an RDF dataset that is automatically generated from WorldCat catalog records and identifies common content in the editions and formats of particular books, sound recordings, and other resources held in library collections.
The next section of this chapter walks through a sample description, starting from a user’s search on WorldCat.org. The rest of the book is about the development of authoritative resource hubs for the key entities that stand behind such descriptions, making it possible to envision a maturation of the initial experiments into a next-generation platform for library resource description. As our projects mature, our commitment in Schema.org has only solidified. Though Schema.org offers the promise of greater visibility by search engines, it is also a large, extensible, and growing vocabulary that is compatible with the goals of linked data and can be interpreted as a de-facto standard. According to an informal estimate offered by R.V. Guha (Dataversity 2013) in late 2013, Schema.org markup has been published on approximately 15% of the Web pages processed by Google. When we started to model bibliographic resources in 2011, there were no other realistic options, either in library standards or in vocabularies published outside the library community that had a comparable scope, depth, institutional support, and adoption rate.
As we have already noted, the first draft of the BIBFRAME model was also published by the Library of Congress in 2012. This is an important milestone in the development of linked data for bibliographic description because it represents a commitment to linked data by one of the most important institutions in the international library community. According to Kevin Ford, a key BIBFRAME architect, “Linked data is about sharing data …” and “…provides a strong and well-defined means to communicate library data, one of the main functions requiring attention in the community’s migration from MARC” (Ford 2012), a point that McCallum (2015) elaborates.
OCLC was invited to participate in the BIBFRAME Early Experimenters’ Group, which was active in 2012 and 2013. Both in closed and public meetings, we have argued that OCLC’s models are compatible but complementary (Godby 2013). The two models have similar primary concepts such as ‘Work,’ ‘Person,’ and ‘Organization.’ But BIBFRAME is being developed as the replacement for MARC, addressing the need for data exchange among libraries in the Semantic Web.
OCLC’s modeling experiments address the problem of integrating library resources in the broader Web. During the past year, while this manuscript was being prepared, the projects led by the Library of Congress and OCLC have advanced in parallel. The Library of Congress has developed the BIBFRAME Implementation Testbed (LC 2015), which includes conversion tools and a discussion forum for interacting with 17 organizations who are conducting pilot tests. OCLC has not participated in the BIBFRAME pilot tests, but has focused instead on refining the models and implementation details described in the following chapters. Though our conclusion about the two modeling initiaves has not changed since 2013, OCLC has begun to collaborate with the Library of Congress to gain a deeper understanding of how the models interoperate. This effort was taking shape too late to be discussed in this book, but Godby and Denenberg (2015) provides a high-level summary of a technical analysis that will be published later in 2015.
1.3 A Technical Introduction
A bibliographic record accessible from WorldCat.org describes a creative work for a library patron who wishes to discover and perhaps gain access to it. Figure 1.6 shows a record for the book American Guerrilla: My War Behind Japanese Lines, which was written by Roger Hilsman and published in 2005 by Potomac Books in Washington, DC, as member of the series Memories of War, which includes other memoirs about World War II that can be discovered by clicking on the link beside the ‘Series:’ label.
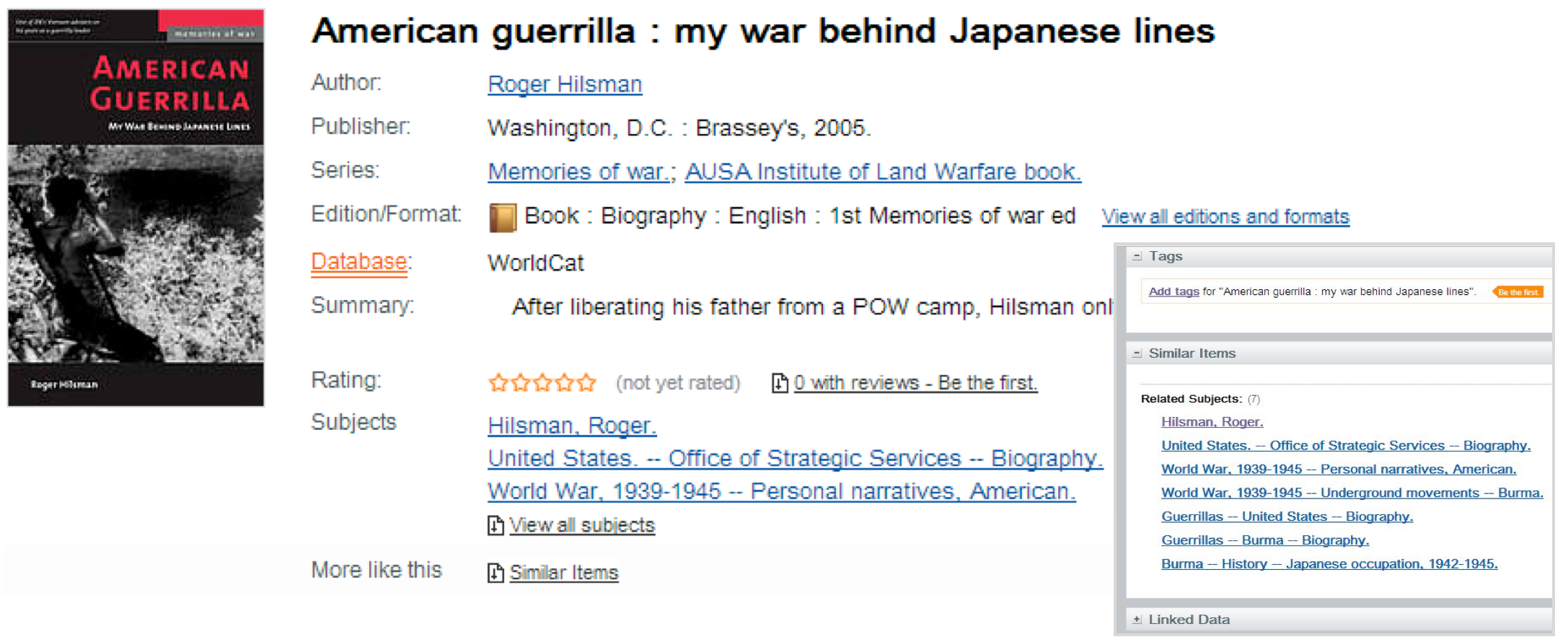
This is only the first segment of the description of American Guerrilla accessible from WorldCat.org, the search interface for the WorldCat catalog. Additional segments provide links to reviews, to the websites of nearby libraries that own the book, to online booksellers such as Barnes & Noble and Amazon.com, and to details that might help the reader obtain the book, such as a physical description and the ISBN 1574886916. Patrons who click on the ‘Similar Items’ link shown on the right side of Figure 1.6 can view this description in the larger web of creative works to which librarians have assigned the same subject headings. It is thus possible to discover a video interview of Roger Hilsman produced by a public broadcasting station based in Boston in 1981, a Ph.D. dissertation submitted to the University of Arkansas in 1999, and many other works about guerrillas in Burma, the Japanese occupation of Burma from 1939–1945, and World War II itself.
The labels on this page from the WorldCat.org interface are available in English and ten other languages. It is a patron-friendly view of a MARC record and is enhanced with RDF statements that can be viewed in a human-readable format from the ‘Linked Data’ section at the bottom of the page, as shown in the inset on the right side of the figure. There is nothing particularly unusual about this description, except that the source record is easy enough for casual readers to understand but complex enough to be interesting and permits us to draw some comparisons with the British Library Data Model in a later chapter. In addition, American Guerrilla is a relatively obscure book that can be contrasted with more famous creative works whose more complex publication histories illustrate issues that the OCLC model is being designed to address, and we will mention it a few more times in subsequent chapters. But in the rest of this section, our goal is to work through the WorldCat description excerpted in Figure 1.7 in deeper levels of detail, ending with a high-level understanding of the RDF markup and a sense of the work that remains to be done.
1.3.1 From a MARC 21 Record to RDF
Figure 1.7 is an excerpt of the corresponding MARC 21 record, which conforms to the standard defined in the ‘MARC 21 Format for Bibliographic Data’ specification maintained by the Library of Congress (LC 2014e). The 100 $a field states that Roger Hilsman is the author, while the 245, 250, 260, and 300 fields contain details about the title, edition, imprint, and physical format of the published book. The 490 $a field lists the title of the publisher-defined series to which this book belongs, Memories of War. Other titles in the series include War in the Boats: My World War II Submarine Battles and Wake Island Pilot: A World War II Memoir, which are also described in WorldCat. The 500 and 520 fields contain free-text or lightly formatted notes. The subject headings listed in the 600, 610, and 650 fields are derived from Library of Congress subject headings, except for ‘guerrilla,’ whose source is not specified in this excerpt. Finally, the 082 field contains a number defined from components of Edition 21 of the Dewey Decimal Classification, which was constructed to capture the subject of this book with enough precision to place it on a library shelf among books with similar topics.

The first task required for converting the MARC record to RDF exploits the obvious correspondences between the semantics of the MARC 21 fields and subfields with the terms defined in Schema.org. Table 1.1 shows a small sample that is relevant to the record shown in Figure 1.7. At this point in the discussion, even before we examine the RDF statements, it is possible to make several broad observations. First, lexical mappings to and from MARC are constantly being defined for the important international Web-friendly standards that have appeared since the 1990s (LC 2008a, 2014f; EDItEUR 2009), whose meaning is also theoretically expressible using set-theoretic relationships defined in OWL (Dunsire et al. 2011) instead of source-target tables, or metadata crosswalks, such as the one shown below. Second, this exercise has convinced many library standards experts (Ronallo 2012), including those at OCLC, that Schema.org is a reasonable starting point for the description of library resources on the Web.

Finally, this exercise already points to the need for an analysis that goes beyond lexical substitution because the conversion from MARC to RDF requires more than simple relabeling. Following established practice in the linked data community, we represent names of classes – or entities – defined in a Semantic Web vocabulary with a capitalized first letter, such as schema:CreativeWork, while properties – or relationships – are represented with a lower-case first letter. All of the terms shown in Table 1.1 are properties defined in schema:CreativeWork, though the use of schema:isPartOf is unsatisfactory for reasons we discuss below. The semantics of the MARC record permit a reader to infer that a schema:creator or schema:contributor is a relationship between a person or organization and a creative work. But the literal references to these classes, which are required links to the real-world entities in a bibliographic description, are only assumed. The same point can be made about simpler properties such as schema:description or schema:numberOfPages, which are two-way relationships between a creative work and a literal string. A formal model is required to acknowledge these classes and properties explicitly, a topic we discuss in detail in Chapter 3.

The RDF markup corresponding to Figure 1.6 is shown in Figure 1.8. It is expressed in the Turtle syntax (Beckett and Berners-Lee 2011), which we use throughout the book because it is only slightly more difficult to read than a Dublin Core description and can be converted mechanically to richer RDF formats using a Web-accessible translator such as RDFLib (Stolz 2014). In Figure 1.8, the main segments in the description are separated by whitespace. From top to bottom, they are the namespace declaration, the primary description, and four secondary descriptions. The namespace declaration contains references to RDF and OWL, the expected RDF infrastructure, and to Schema.org. The namespace ‘madsRDF’ refers to the model of library authority files maintained by the Library of Congress (LC 2012), which is slightly richer than SKOS, a topic we discuss briefly in Chapter 2.
The primary and secondary ‘description’ blocks represent <rdf:Description> statements and have the same structure. The first line is a URI reference to a real-world object; the second line starts with ‘a’ and represents the <rdf:type> declaration for the object; and the last line is a period marking the end of the block. The intervening statements identify properties of the object being described. In Figure 1.8, the URI <http://www.worldcat.org/oclc/52347585> refers to the book American Guerrilla authored by Roger Hilsman. The referent of such URIs is ontologically complex, but here it is accurate enough to say that it refers to a schema:Book, which is a subclass of schema:CreativeWork. This book is a concrete object and is associated with a WorldCat Work description of the content, a subtlety that will be described in the model of creative works in Chapter 3. The remaining rdf:Description blocks are conceptually simpler and refer to the people, places, organizations, and topics that have been described in traditional library authority files, many of which have been modeled as linked data. This is the subject of Chapter 2.
The rdf:Description blocks exhibit different degrees of technical maturity, which can be read off the format of the data in the predicate. Those with URIs are the most fully realized. For example, the same VIAF identifier is a predicate of schema:author and schema:about, which resolves to the person named Roger Hilsman who wrote American Guerrilla, a restatement of the fact that a memoir is both by and about the author. In the corresponding subordinate description, the property madsrdf:isIdentifiedbyAuthority is used to state that the same person has also been described in the Library of Congress Name Authorities file. In sum, these statements identify Roger Hilsman as a unique individual, establish his identity through a persistent URI, and aggregate information about him from multiple published sources.
RDF predicates containing quoted strings, however, are red flags in the linked data paradigm. They need more attention. Though some, such as titles and descriptions, are intrinsic string literals that require no further processing, most of the others represent strings that have not yet been promoted to ‘things.’ This is true even if the predicate is a string whose RDF type and properties can be inferred from the MARC source. For example, the compound statement schema:about [a schema:Intangible “Office of Strategic Services”] is mapped to Schema.org as an ‘intangible thing’ from a MARC 653 field, indicating that the string has no source in a library authority file. Thus the RDF statement is no more informative than the MARC source. Nevertheless, evidence exists elsewhere in the record that ‘Office of Strategic Services’ is modeled as an organization in the linked data version of FAST, where it is associated with a persistent URI. A human reader can detect this redundancy, but a simple machine process cannot. Likewise, the slightly more complex statement schema:publisher [a schema:Organization; schema:name “Brassey’s”] is a paraphrase of the MARC 260 $b description of a publisher as an organization with a particular name. But ‘Brasesy’s’ is still a string and not the name of a recognizable real-world thing because it is not linked by a URI to a description in an authoritative entity hub. A more sophisticated data-mining process would discover that ‘Brassey’s’ is the name of a publisher and is associated with URIs in several library authority files that have been modeled as linked data.
The statement schema:isPartOf “Memories of War” exposes another unfinished task. The statement uses the property isPartOf, defined for schema:Thing, to describe American Guerrilla as a member of a series. But Memories of War is a collection, not a single creative work, a fact that cannot be expressed in the current version of Schema.org. Problems such as this one are being addressed by the W3C-sponsored Schema Bib Extend Community Group (Schema Bib Extend 2014d), whose membership includes representatives from OCLC and the broader library and publisher metadata standards communities. This group has been convened with the purpose of proposing extensions to Schema.org that would be formally included in the standard. Discussion is underway to define Collection more generically as a subclass of schema:Thing and deprecate the already defined schema:CollectionPage, which applies only to schema:WebPage, a subclass of schema:CreativeWork (Schema Bib Extend 2014a). One outcome of this experience is the first draft of an extension vocabulary named BiblioGraph (BGN 2014a), which is formally compatible with Schema.org and contains definitions of classes and properties required for a model of the domain of library resource description that can be shared on the broader Web. These topics are described in detail in Chapter 3.
The URIs shown in Figure 1.8 conform to the Cool URIs convention (Sauermann and Cyganiac 2007), which are simple, stable, manageable, and resolve unambiguously either to an information object or a real-world object. OCLC’s URIs resolve only to real-world objects—i.e., to the people, places, organizations, objects, works, and concepts that are referenced in bibliographic descriptions, and not to database records or other documents. Information objects are resolved by the HTTP protocol that returns the status code 200, which we refer to in this book as ‘HTTP 200.’ A real-world object is identified through the HTTP protocol that redirects the request to a document about the object and returns the 303 status code, which we abbreviate as the ‘HTTP 303 redirect.’ By implementing the HTTP 303 redirect protocol, the data architect acknowledges that Roger Hilsman himself cannot be delivered when his VIAF identifier is dereferenced, but an authoritative document about him can be delivered instead—namely, a VIAF description, which we discuss in Chapter 2. The Cool URIs convention also makes it possible to define seemingly unreal things such as concepts, ghosts, and unicorns as real-world objects if the Web can be viewed as a corpus of documents and there is some consensus about what they refer to. Thus, a document request resolved with an HTTP 303 redirect can be used to define a kind of machine-processable reference by denotation, as Panzer (2012) argues.
1.3.2 Managing Entities in the Web of Data
Stepping back from the minute details of the above example, we can observe that nearly all of a reasonably complex MARC 21 bibliographic record can be rendered as some form of linked data, labeled primarily with vocabulary defined in Schema.org. URIs replace most of the strings in the source record and are resolved by a protocol that recognizes the real-world objects in the description. This is a success story and a milestone toward the long-term goal of releasing the rich contents of library metadata to a wider population of data consumers both inside and outside the library community.
The linked data paradigm is attractive because successful results offer the promise of machine-understandable data that can be shared on the Web beyond the library community. For the first time in the history of Web data architecture, the linked data paradigm also embodies a computationally realistic theory of reference, encoded in the distinction between the web of documents and the Web of Data.
But the Semantic Web theory of reference is immature and not yet implemented at an actionable scale. Progress requires the identification of real-world objects and the creation of authoritative descriptions, or entity hubs, that are associated with URIs resolved as references to things, not documents. Achieving this goal requires a set of processes that is deeper than the mapping of individual records to Schema.org or other Semantic Web standards because the core problem is to associate a text string such as ‘Shakespeare’ as the author of Hamlet with the playwright who lived in the 16th century. Establishing this connection typically requires the application of data mining algorithms on a corpus of documents. Over time, authoritative entity hubs are enriched as more data publishers contribute their expertise to the identification of globally important entities such as William Shakespeare, ‘dark matter,’ Google, and Charles Darwin’s On The Origin of Species.
Wikidata and DBpedia can be viewed as early drafts of entity hubs that are already widely referenced. But entity hubs produced from resources managed in the library community are still experimental, though early tests demonstrate that effective prototypes can be derived from authority files and large aggregations of legacy bibliographic descriptions such as WorldCat, the European Library (TEL 2014b), and Europeana (Europeana 2014). But such projects need to be expanded in scope and depth to ensure that resources managed by libraries are more visible to the information-seeking public because they are interconnected with authoritative entity hubs that are highly referenced throughout the Web. This outcome also motivates the design of the LibHub project (Miller 2014), whose goals are congruent with the linked data projects described in this book.
To set a direction that is realistic but ambitious enough to have impact, OCLC has focused the current phase of our work on six key entities—and the web of relationships among them—that can be identified in traditional library authority files and bibliographic records and reformulated as linked data: ‘Person,’ ‘Place,’ ‘Concept,’ Organization,’ ‘Object,’ and ‘Work.’ More narrowly specified, our goal is to build a baseline proof-of-concept demonstration that establishes common ground with other initiatives in the library standards community by focusing on library resources such as monographs instead of less-well-understood digital and multimedia formats, and focusing more on the publishing of linked data than the consumption of it.
It may be less obvious that our interest in key entities also defines a set of priorities. First, it is a directive to start with where users are—somewhere on the Internet, with an information request. We must build descriptions that do a better job of fulfilling their needs by connecting the expertise now sequestered inside library catalogs to the broader Web using a broadly deployed ontologies such as Schema.org, FOAF, and SKOS, and the W3C-defined protocols for interpreting them. Second, the key entities must be identified, defined in hubs of authoritative information grounded in library descriptive practice, and associated with persistent, globally unique identifiers. This format ensures that the entities are visible to search engines and data providers outside the library community. With respect to current metadata management workflows, these activities can be interpreted as a focus on the representation and architecture of authorities, deferring to the future the more difficult task of reimagining the act of cataloging. Finally, these entities must be interconnected through relationships, or RDF properties, to form a model of the relevant domain.
The projects described in this book have been scoped with an awareness of the progress made so far in library linked data projects. After all, five of the six key entities—all but ‘Object’—make up the content of traditional library authority files, for which linked data models were first defined and are now commonplace. OCLC’s contributions to this effort are the subject of Chapter 2 and culminate with a description of VIAF, whose semantics have evolved beyond that of the traditional library authority file to an authoritative hub with inbound and outbound links to the broader Web. Chapter 3 reports on a set of projects that recognize the user’s understanding of a Work such as Hamlet as an abstract information request and interprets its various physical realizations as Objects that offer a range of fulfillment options. The result is a lightweight and flexible model of creative works inspired by the conceptual model for the Functional Requirements for Bibliographic Records, or FRBR, and expressed primarily in Schema.org. Since authoritative hubs for all six key entities must be created through text and data mining, Chapter 4 surveys relevant research projects that have been conducted at OCLC using advanced algorithms that are required when the information that can be extracted from authority-controlled and other highly structured data is eventually exhausted. Finally, Chapter 5 summarizes the arguments for the approach we have taken and answers questions about how the work will be extended, where the limitations lie, and how linked data models of authoritative hubs will affect future descriptive practice.
1.3.3 A Systems Perspective
OCLC’s published linked data markup, the underlying model, and the supporting data resources can be derived only from a complex set of processes involving human analysis, metadata mapping, format conversion, data and text mining, and system-building that is constantly being refined to reveal more and more detail. In its earliest drafts, the model underlying the linked data output may be fully consistent with the current generation of standards and production systems. But Figure 1.9 shows the bigger picture. The processes listed in the box with the title ‘WorldCat.org production stream,’ shown in green, represent the latest iteration of a decades-old production stream, which maps from non-MARC inputs, normalizes critical fields such as ISBNs, corrects erroneous subject headings, and removes duplicates, producing results that are visible in the user-oriented displays derived from MARC records in WorldCat. The box with the title ‘Experimental processes,’ shown in blue, lists some of the the two-year-old experimental process flow that generates two outputs: the RDFa markup accessible from WorldCat.org, and a slightly richer RDF dataset with the contents of the entire MARC record that reflects a large, yet-to-be-modeled residue, as well as the results of modeling experiments that are too tentative to be published in a production service or are incompatible with the MARC standard and a record-oriented architecture.
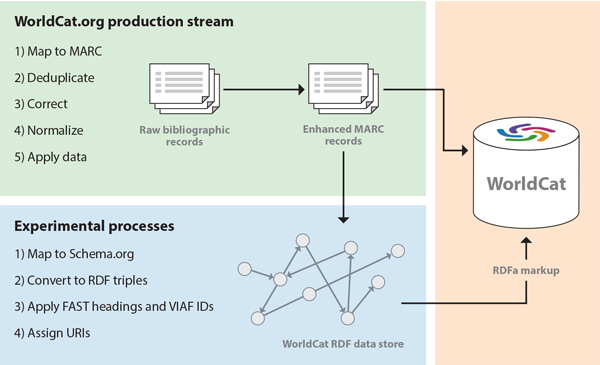
Other leaders in the library community have described a similar architecture. For example, Gildas Illien, Director of the Bibliographic and Digital Information Department at the Bibliothèque nationale de France, argues in a recent interview (Illien 2013) that libraries cannot afford to wait until their linked data is perfect because they are risking irrelevance by not claiming their rightful place in the Web of Data as early as possible. A better strategy is to demonstrate what is mature and useful now and iteratively improve it as the models are refined and new details are implemented. The initial implementations will be too impoverished to substitute for the legacy systems and will even depend on them, thus generating a need to convert legacy data to the new standards and creating a more complex transitional architecture that enables the old and new systems to coexist. But as they mature, the new systems will become more and more capable of standing alone and will eventually replace the old ones. Illien’s remarks were about the linked data experiments being conducted at his institution, but they are an apt description of the evolutionary path that has been defined at OCLC.
The French dataset, first published in 2011 and accessible from http://data.bnf.fr, contains links to 200,000 authors, 9,250 creative works, and 170,000 subjects, representing 40% of the references in the French National Catalog, with plans underway to convert the rest. As in WorldCat, the linked data representations are produced by mapping from existing library metadata standards such as MARC and EAD to the corresponding semantics of a new data model that refers to a small set of real-world entities and is capable of generating new output syntaxes such as RDF/XML, RDF/Turtle, and JSON. The effort has already paid off with an award-winning integration of multiple catalogs. It is now possible to issue a single search that delivers consolidated information from the central catalog managed by the library, as well as collections of archival descriptions and digitized objects—resources that once co-existed only as isolated data silos. But as reported by The European Library (TEL 2014a), an even better outcome is that 80% of the hits now originate from the broader Web, bypassing the library’s locally maintained search intake systems altogether.
The British Library has also reported a positive outcome from the linked data modeling experiment (BL 2014b). Since 2011, the British National Bibliography has grown into a semantically rich, interconnected network of links to people, places, dates, and subjects in 3.5 million books and serials published in the UK and Ireland since 1950. In 2014, British National Bibliography elicited 2 million transactions per month, has received national accolades, and has been formally incorporated into the British national data infrastructure.
Finally, the project sponsored by the Oslo Public Library has achieved an important milestone, as described in Rekkavik (2014). The linked data version of the Oslo library catalog was developed with a dependency on the legacy production system not unlike OCLC’s configuration depicted in Figure 1.9. The experiment has served as a testbed for research projects with goals similar to those pursued at OCLC, which have yielded tools for converting MARC to RDF and descriptions that recognize entities and relationships first defined in the FRBR model of the library catalog. But modeled as linked data, Oslo’s next-generation catalog can support a seamless integration of physical and digital resources. The catalog can also bundle descriptions of works in the library collection with related works accessible from the wider Web. Since these innovations cannot be supported in the old standards, the Oslo Public Library has announced the radical step of dropping MARC as a format for resource description. Thus the Oslo linked data experiment has matured to the point that it can stand alone because it now has more functionality than the legacy production system.
1.4 Chapter Summary
The successes reported by the Bibliothèque nationale de France, the British Library, and the Oslo Public Library provide a glimpse into the workings of the library of the future, one in which resources in a library’s collection are more machine-understandable, are more integrated with the broader Web, and are more consistent with conventions that facilitate consumption by the world’s general-purpose search engines, where users are increasingly more likely to discover them. An international consensus is reaching the conclusion that the data architecture for the next-generation library will be built on the data standards and Web protocols discussed in this chapter.
The argument for doing so has multiple layers. The simplest argument is that the new reality is a Web environment in which data standards and communication protocols highlight the need for more structured data with a more broadly understandable meaning derived from richer domain models—enabling machine process to act on data that was once merely displayed, to echo the passage quoted at the beginning of this chapter. The library community has no choice but to operate in this environment, both as consumers of the new standards and as contributors who ensure that the world’s intellectual heritage is justly represented. Stated more colloquially, this is the external argument for libraries becoming more ‘of the Web’ and not merely ‘on the Web.’
But the internal argument is also compelling. Library standards for resource description date from the dawn of the computer age for civilian applications and have reached the end of their useful life. In the 1960s, a ‘Machine-Readable Catalog’ (or MARC) record was a major advance over a printed catalog card. But these records are understandable only in the library community—and even there, machine processes are hampered because most of the important assertions are encoded as human-readable text, including numeric values such as record identifiers and ISBNs. As Coyle (2012) pointed out, an analysis of more Web-friendly standards such as Dublin Core and ONIX produces a list of milestones that lead to deeper levels of machine understanding because they place a greater premium on converting text to data, data to unambiguous or controlled vocabularies, and records to statements. These milestones can be understood as the preprocessing steps required for publishing linked data, or as inputs to the processes that generate RDF datasets conforming to the criteria listed on Tim Berners-Lee’s coffee cup reproduced in Figure 1.5.
Thus there is incremental value in following the path from databases of human-readable records to five-star networks of RDF statements because each milestone promises an outcome that is independently useful. The first is data that is more structured, more normalized, and easier to maintain. A later outcome is data that conforms to an actionable domain model using published standards that renders it understandable outside the context that created it. The ultimate result is data that can be acted upon to produce greater visibility on the Web and syndication by general-purpose search engines.
Many details remain to be worked out in the context of experimentation and research, both at OCLC and elsewhere in the library community. In other words, libraries have just entered the Semantic Web. The focus is on defining descriptive standards and models that conform to them, developing proofs of concept and compelling demonstrations, and generating results that may even exert influence on the still-evolving Web standards. The rest of this book describes some of the next steps toward these goals being undertaken at OCLC. Such ambitions are large, but experiments with linked data have already improved the user experience with library resources and exposed their value more broadly.