Library Linked Data in the Cloud
OCLC's Experiments with New Models of Resource Description

Authors
Jean Godby, Ph.D.
Senior Research Scientist
Shenghui Wang, Ph.D.
Research Scientist
Jeff Mixter
Sr. Software Engineer
Chapter 5: The Library Linked Data Cloud
- 5.1 A Look Back and Forward
- 5.2 Next Steps
- 5.3 A Few Lessons and Some Persistent Challenges
- 5.3.1 Conceptual Challenges
- 5.3.2 Technical Challenges
- 5.3.3 Environmental Challenges
5.1 A Look Back and Forward
The projects described in the previous pages highlight the importance of entities and relationships in library data, which are already expressed in legacy standards, but are now recaptured in a format that is more capable of broadcasting the value of library collections to the broader Web. Focusing on the identification of six key entities—Person, Place, Organization, Concept, Work, and Object—the exposition describes the process of designing Linked Data models and discovering evidence for them through the retrospective conversion of library authority and bibliographic records.
Some might object that the scope of the projects has been too narrow because our models describe only monographs, not digital or multimedia resources; and because the exposition has focused on the publication of linked data, not its consumption. Our attention has been restricted to the publication of identifiers that fall squarely within the scope of traditional librarianship—for creative works, not raw data, and for book authors, not unpublished researchers or agents in a collection of historical documents. But work we have described is a baseline that establishes continuity with the past. It shows where library linked data models have come from and how they can be populated. It makes the case that these models can become a core component of the architecture for the next generation of library resource description. Our goal in writing this book is to establish common ground for discussion with librarians, standards experts, and computer scientists beyond OCLC and to serve as a springboard for more sophisticated work.
5.2 Next Steps
We have argued that the development of models for library resource description can be grounded in Schema.org—not only because it is the most widely adopted vocabulary for exposing structured data on the Web and is recognized by the world’s major search engines—but for the far simpler reason that it is a sophisticated standard first published during a time of historic instability in the evolution of standards for library resource description. In our first experiments with Schema.org in 2011, we created descriptions of creative works, reformulating bibliographic records as graphs, but we have recently republished the RDF models for FAST and VIAF with references to schema:Person, schema:Organization, schema:Place, and schema:CreativeWork—the top-level concepts described in library authority files and aggregations of them.
We believe that the case for using Schema.org is compelling, despite our own initial reservations and those that continue to be expressed by colleagues and peers in the library community who are solving similar problems. But what happens to the models we have developed if the most important search engines stop supporting Schema.org? Right now, such a move seems unlikely, given the utility of structured data for search engines and the fact that Schema.org is the first Semantic Web standard to have gained widespread acceptance and the rate of adoption is increasing (Guha 2014). The survival of Schema.org is not guaranteed, of course, at least not in the timeframe presupposed in the traditional practice of librarianship. The MARC standard was first published over fifty years ago; will Schema.org persist into the 2060s? Even if it does not, Schema.org has already served as a vehicle for consolidating the best ideas about knowledge engineering on a large scale, starting from its roots in Cyc in the early 1980s and continuing with the innovations introduced by its growing user community, including the Schema Bib Extend group managed by OCLC’s Richard Wallis. Through engagement with Schema.org and the Semantic Web principles it represents, we have become accustomed to the discipline of modeling the things in the world that users care the most about. If that goal is achieved, it is the best insurance against future disruption because such models can be more easily mapped to whatever ontology takes Schema.org’s place.
In fact, some leaders are already making the much stronger case that it is not only possible to align the descriptive standards preferred by librarians with those adopted in the broader Web, but that it is necessary and even more important than a continued investment in library-community standards. For example, Kenning Arlitsch, Dean of the Library at Montana State University, argues that recent attempts to modernize library standards have been met with mixed results, concluding that:
“If we believe there’s value to making our materials discoverable and usable to a wider audience of people, then we must begin a concerted effort to make our metadata interoperable with Web standards and to publish to platforms that more people use. Well-intentioned librarians and archivists have spent decades developing and implementing data interchange formats that simply haven’t been adopted by the Internet, and as a result we struggle to make our materials visible and usable. Is it appropriate, or even responsible, for us to continue to push an environment where people aren’t, or where they don’t even seem to want to be?” (Arlitsch 2014, p. 619)
Another set of concerns stems from observations about the scope and shape of Schema.org. If it is an ontology designed primarily for describing products and services traded in the commercial sector, how can it be detailed enough to describe library resources with the care required for long-term stewardship? We believe that this question can be answered by a ground-up approach: developing models derived from Schema.org, testing them on real instance data produced by the library community, and improving them with input from domain experts. That is how the models described in this book were developed and they are only the foundation for what we believe is possible.
For example, digital copies of scholarly articles and monographs present one opportunity to explore as-yet unused properties defined by Schema.org and address a pressing need for improved library resource description. Figure 5.1 shows the relationship between a hardcopy monograph and a PDF version, using the property schema:encodesCreativeWork. Since a PDF representation may consist either of a single large file or a set of separate files containing chapters, pages, or other logical components, it can be modeled as a hierarchical collection with schema:isPartOf relationships to the parent.
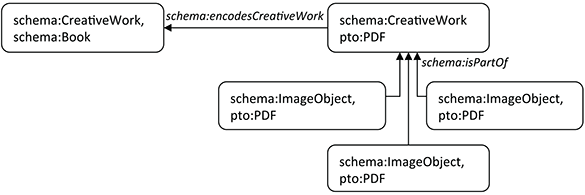
With this model, it is possible to state that the two versions have the same author, title, subject, and exactly the same text. But in a university library, the two versions would probably have different terms of access: the monograph might circulate to library-card holders for a limited time period, while the PDF file could be accessed for any length of time with or without authentication as a member of the local community. In the language of the Holdings model described in Chapter 3, the PDF and hardcopy versions are creative works realized as different kinds of schema:Product, for which different terms of accessibility can be specified in a schema:Offer description.
These relationships are used for a different purpose in Figure 5.2, a slight elaboration of the model depicted in Figure 5.1, which depicts a high-level model of a journal article, expressed in recently published vocabulary defined by Schema.org. At the center is schema:Article, which has a schema:isPartOf relationship to a journal issue, coded as schema:Issue. An ‘Issue’ is a subdivision of ‘Periodical,’ coded as schema:Periodical, which has a schema:ISSN property. Not shown is an analogous relationship to schema:PublicationVolume. As in Figure 5.1, the contents of a journal article can be realized either as a physical document or a digital file. Since the ISSN is a product model analogous to an ISBN, the journal article, volume, issue, and periodical have a physical presence, which would trigger the assignment of a value from the schema:Product class and permit the statement of a schema:Offer in the OCLC model of Works. The diagram shows that a printed journal article is available from Montana State University and a digital surrogate is accessible from EBSCO (2015).
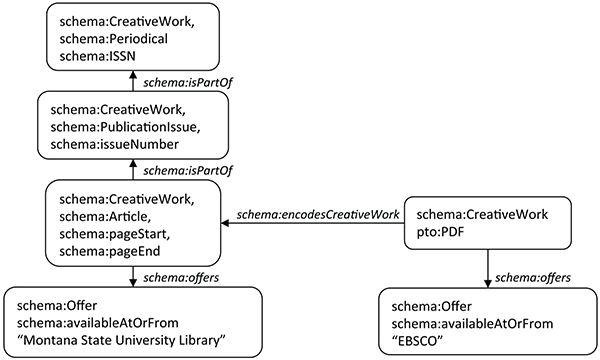
The model shown in Figure 5.2 is only a draft and many details still need to be specified, but it builds on previous work and shows a new area of interest for linked data models at OCLC. It is an extension of the OCLC Model of Works described in Chapter 3 and is expressed almost entirely in Schema.org. It also permits the expression of subtle relationships in a machine-processable format that are coded only as free text in current standards. For example, Figure 5.2 reveals that models of holdings are fundamentally different for physical and print resources: a library holds—or ‘has’—a physical object that can be put into the hands of a patron, while the same library does not own but merely licenses a digital surrogate from a commercial provider.
Finally, the model illustrates the workflow we have developed in the past year. The first draft of the model is defined using Schema.org and gaps are identified. In this example, ‘PDF’ is represented in the pto: namespace because it is not yet defined either in Schema.org or BiblioGraph. But a serviceable definition is available in the Product Types Ontology (PTO 2015), which is the output of a software process that converts concepts defined in Wikipedia to a machine-understandable format and models them as subclasses of schema:Product. When the model matures and the definition of ‘PDF’ needs to be upgraded, we can define it in BiblioGraph with input from other experts in bibliographic description. But since a good definition of ‘PDF’ is likely to be needed by other communities besides librarians and publishers, this term is a candidate for inclusion in Schema.org. Using BiblioGraph.net, we can pinpoint the location of ‘PDF’ in the larger ontology, making minor adjustments where necessary and lobbying the managers of Schema.org to do the same. The structured parts of the journal article were defined in a similar fashion by the Schema Bib Extend Community Group and were formally absorbed into Schema.org in September 2014 (Wallis and Cohen 2014), (Wallis 2014a). Though additional effort will be required to define vocabulary that expresses some of the fine details in the accessibility contracts as properties of schema:Offer, the procedure for doing so is already in place. This project is far from mature, but Mixter, OBrien, and Arlitsch (2014) describe a project using the same workflow that has already produced a working model of theses and dissertations in the context of a university institutional repository.
We are often asked if the linked data models OCLC has developed are detailed enough to replace MARC as the standard for data storage and communication between libraries. It is too early to know. Other library-community initiatives, most notably BIBFRAME and RDA, have been addressing use cases for the long-term management of library resources and the sharing of data among libraries.
A possible alignment of these standards with the OCLC model of Works is shown in Figure 5.3; it sketches the same landscape as Figure 4.1 in Godby (2013) from a slightly broader perspective. At the core is a detailed description that supports library functions described in a native library standard. The elements of the description that are comprehensible and relevant to the broader Web are mapped to Schema.org and candidates for proposed Schema extensions defined in BiblioGraph. Since only a small number of the concepts in the domain of library resource description can be exposed in an easy-to-use vocabulary that serves the needs of the entire Semantic Web, the analysis required to optimize the exposure of our resources is no different from that being conducted by other user communities, such as medicine, sports, the automotive industry, and others mentioned in Guha (2014). Nevertheless, if the library standards community succeeds in engaging with the managers of Schema.org, the mapping from native standards will be achieved with minimal loss of information.
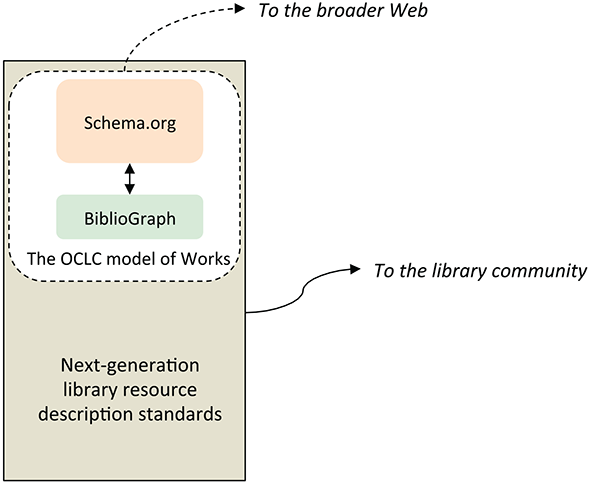
Some have asked the arguably less important question about the relative size of the two main areas in the diagram. The short answer is that it shouldn’t matter because the description that can be exposed to the broader Web should be a proper subset of the description required for internal library processes. Libraries benefit if that subset is as large as possible, but we don’t know whether the subset is large or small. Perhaps it is relatively large because it may be possible to say more with modern standards that encode entity-relationship models and have a built-in vocabulary for describing resource types that didn’t exist when MARC was first defined. But a more nuanced answer recognizes that the task of resource description will change in the new environment. For example, the development of authoritative hubs implies an expanded role for authority control and a diminished role for original description, but the hubs themselves require maintenance that will be absorbed into a human-guided workflow. As we pointed out in Chapters 3 and 4, the assignment of URIs is most reliable when the source is an authority record or a controlled access field in a MARC record, both created from human expertise; other sources require text-mining algorithms that also require human input, usually in the form of training data. When the description of library resources is more broadly integrated into the Semantic Web, however, some tasks may no longer be necessary. For example, copy cataloging would become obsolete in a data infrastructure featuring persistent URIs for Works and Manifestations. Instead of making a copy of a record, librarians would create a statement that includes one of these URIs, supplementing it with local detail required to describe an individual item and its availability. In addition, descriptions of resources originating from the publisher supply chain would be usable in their native forms if publishers produced bibliographic descriptions modeled in Schema.org instead of ONIX, with which it is compatible.
As we have pointed out, the OCLC projects began to take shape at the same time as experiments and standards initiatives in the library community with other primary goals, producing models with comparable granularity. But maturation required a period of introspection, as we developed resource entity hubs and a more sophisticated workflow for engaging with Schema.org. The sponsors of BIBFRAME and RDA did the same as they developed vocabulary and refined the details of their models (LC 2014b; DNB 2014). But now it is time to join forces again because the path forward looks unclear to those who must build out the new standards for library resource description. Accordingly, OCLC researchers are serving as advisors on two grant-funded projects, Linked Data for Libraries (LD4L 2015b) and BIBFLOW (BF 2015), whose goal is to produce BIBFRAME descriptions in a library cataloging environment. In addition, OCLC and the Library of Congress are collaborating on a technical analysis that shows how BIBFRAME and the OCLC model of Works would interoperate in a description of a library resource that cannot be described easily in MARC and requires the specialized vocabulary developed in the library community. A high-level summary is now available (Godby and Denenberg 2015).
5.3 A Few Lessons and Some Persistent Challenges
The projects described in the previous section will be developed through the familiar cycle of analysis, design, implementation, public release, and iterative improvement, following the same process that produced the results described in earlier chapters. We have learned many lessons, all starting from the realization that though the linked data paradigm is rooted in good ideas of the past, it is radical, unsettling, and still experimental. Thus it should not be surprising that linked data meets resistance among targeted users as well as colleagues who are tasked with its implementation. To increase the comfort level, we participate in community standards initiatives and public conversation. We communicate the linked data vision, highlighting the successes of others when it is not quite visible in our work. We provide many pathways to understanding, including publications, presentations, workshops, collaborative projects, published datasets, demonstrations of our technology stack, and even one-on-one tutorials. To address more narrow technical concerns at OCLC, we listen to colleagues who are trying to consume the data we are publishing. We discourage prolonged investment in solutions that mix old and new paradigms because they are backward-looking and difficult to maintain. Instead, we recommend investment in more robust prototypes, which are developed in accordance with the lifecycle requirements that govern traditional products and services. Whenever a roadmap for a linked data resource delivers a feature in time for a product to make use of it, we gain an ally.
To get this far, we have also confronted many challenges, but some are persistent and perhaps endemic to the enterprise of publishing linked data for public consumption.
5.3.1 Conceptual Challenges
Despite the apparent complexity of the linked data paradigm, as documented in a growing collection of standards documents from multiple communities of practice, only some of which were discussed in Chapter 1, producing linked data reduces to three straightforward tasks. The first is the development of a model of real-world entities and relationships for a domain of interest. The second task is the production of instance data, or an RDF dataset, which mentions these entities and provides more information about them that could be mined by a subsequent process. Finally, the authoritative documents that define the entities must be associated with a persistent identifier, or URI, which is embedded in the documents that mention them. References to the real-world objects beyond the documents is established when the URI is resolved with currently available Web protocols. We have argued throughout this book that librarians are already familiar with these tasks. The linked data paradigm is simply a set of conventions that promises greater interoperability and persistence for the outcomes that their work already generates.
But model design is difficult. Though an obvious starting point is the collection of prior successes, we have learned that even the models of ontologically simple objects must be assembled from multiple sources and will probably be works in progress for the foreseeable future. For example, we argued in Chapter 2 that the model of ‘Person’ encoded in a library authority file describes a unique individual who is attested either as an author or a subject in the published record. The simplest acceptable machine-processable model of ‘Person’ for the domain of librarianship requires one or more names, a unique identifier, a set of properties that identify lifespan dates, a connection between the Person and the Work, and more fundamentally, a connection between the Person and the modeled description. But no single published model of the ‘Person’ entity contains all of these properties and the most recent model of VIAF had to be derived from library authority files and supplemented with classes and properties defined in multiple Semantic Web standards, such as schema:Person, foaf:focus, and skos:Concept.
In addition, the growth of VIAF and other entity hubs for Persons will exert pressure for even more properties that describe affiliations for professional researchers and define a larger set of roles of creators and contributors in the production of raw research outputs and multimedia objects, which may not be formally published but disseminated through other channels. The result will be an improvement over current descriptive practice, but it will be obtained through a process of continual refinement as new use cases are considered. As we pointed out at the end of Chapter 2, the same process will undoubtedly guide the creation of a linked data model of the ‘Place’ and ‘Organization’ entities, though current clues indicate that these models may well come from outside the library community, as will the resource hubs themselves. For example, Smith-Yoshimura et al. (2014) reports that major universities are already building authoritative hubs that describe their own researchers, though they are not necessarily modeled as linked data. Even so, this new landscape is an improvement over current library descriptive practice and a validation of the linked data paradigm, which promotes the value of sharing the burden of description of the real-world objects that are important to multiple communities.
Regardless of how these entities are modeled, the assignment of identifiers to individual people, places, and organizations is conceptually straightforward. But the same cannot be said of concepts or topics, the other category of entities described in library authority files. For example, O’Neill (2014) observed that only 5.8 percent of the Library of Congress subject headings that appear in bibliographic descriptions in WorldCat are said to be established and have corresponding LCSH authority records; as of January, 2014, 24.8 million headings do not. From a linked data perspective, this result implies that no resolvable URI can be assigned to nearly 94% of the LCSH headings accessible from the WorldCat cataloging data because they do not have unique identifiers or authoritative descriptions. This analysis also reveals that most of the unauthorized headings are topical subjects. They are an expected consequence of the LCSH design, which has been labeled ‘synthetic’ by classification experts because it features a small set of editorially maintained terms and a rich set of production rules applied by catalogers to create unique headings that describe the object in hand.
To be more precise, the O’Neill statistics overestimate the size of the problem with the LCSH topical headings because some of the unauthorized terms reflect the natural rate of vocabulary growth that can be managed in an editorial process—as more people, places, and organizations appear in the published record and cultural change produces new things to talk and write about. As we pointed out in Chapter 2, complex headings built from established terms can also be assigned multiple identifiers, such as ‘Burns and scalds—patients,’ whose meaning can be interpreted as the union of ‘Burns and scalds,’ with a URI containing the identifier ‘sh85018164’ and ‘Patients,’ with a URI containing the identifier ‘sh00006930.’
But a generic solution is elusive because of what linguists would recognize as a fundamental difference between a vocabulary and a grammar: the terms in a vocabulary can be counted, but the outputs of a grammar with productive, or recursive, rules cannot. Thus it is impossible to assign identifiers to all of the sentences in English or Chinese because they form an infinite set, which can expand whenever a speaker or writer says something. But even if such assignments could be made, it would be an absurd task to identify the sentences that are worthy of curation and associate those expressing the same or related thoughts. This is an upper limit in the creation of linked data from natural language.
On a smaller scale, this is the problem exhibited by library authority files with a synthetic design. The number of catalogers producing unique headings as part of their normal workflow is far greater than the number of editors who can upgrade the authority files that have been affected by their work. We agree with O’Neill that the upper limit can be sidestepped by populating authoritative linked data hubs with subject headings built with an enumerative, not a synthetic design, which feature a larger vocabulary and a minimal set of production rules. We argued in Chapter 2 that FAST is one such scheme; and it is a subset of LCSH, in which every term is established. In Chapter 1, we pointed out that FAST headings have been algorithmically applied to the experimental version of WorldCat from which the RDFa markup is published, using the publicly accessible LCSH-to-FAST conversion program (OCLC 2011a). Thus we can assign URIs to many of the cataloger-supplied topical subject headings accessible from the WorldCat cataloging data through an alternative route.
5.3.2 Technical Challenges
The technical goal of the projects reported in this book is to develop full-sized implementations, not small prototypes. At the outset, we were unsure if it was possible to build the RDF datasets of the required size with real-time access. But as of August 2014, we can report the following statistics from datastores that can be queried from reasonably responsive interfaces: 300 million RDF triples in the Dewey Decimal Classification; 2 billion triples in VIAF; 5 billion triples in WorldCat Works; 15 billion triples in the WorldCat Catalog; and approximately 5 trillion triples in a larger corpus accessible from WorldCat.org that includes descriptions of e-journal articles.
In short, our tests have demonstrated that we can work at the scale required to address the most important problems in the domain of library resource description with a technology stack that consists primarily of open source utilities. In more human-centered terms, OCLC has put together a workflow that automates the conversion from legacy standards, facilitates data analysis and model development, and creates RDF outputs that are capable of standing alone and can coexist with legacy systems. Our development environment is designed to engage collaborators with diverse skill sets, including subject-matter and modeling experts who are not professional programmers as well as software engineers with industry-standard backgrounds in SQL database design, XML processing, and Java development. The details of our technical environment have to be deferred to a separate communication, but a summary is offered in Mixter, OBrien, and Arlitsch (2014).
The primary output of the OCLC linked data implementation is a large network of data that conforms to an entity-relationship model of library resources, in which machine-processable statements can be made that were not possible in the legacy standards. These statements can be understood across multiple data stores inside OCLC or elsewhere in the library community and can be consumed by third parties without the need for dedicated ‘reader’ software. This is a major technical achievement because it is a proof of concept for the infrastructure that can broadcast the value of library collections to the broader Web, where users are most likely to begin their quest for information.
But given our primary use case and our endorsement of Schema.org, the ontology recognized by the world’s most prominent search engines, we are seeking an even bigger reward: greater visibility for libraries on the Web through syndication. But right now, ‘visibility on the Web’ has multiple interpretations. To some, it is appropriate structured data returned from a Google search, such as the before-and-after screenshots of the Google Knowledge Card for the Montana State University Library, whose vital facts appeared in the correct form only after the authors had submitted an article about their institution to Wikipedia (Arlitsch et al. 2014). To others, visibility is measured in increased clickthroughs from external sources; and to others, it is the appearance of their structured data in Google’s Webmaster tools. These are tantalizing hints that data has arrived at its intended destination, but questions remain about how it is processed by search engines and how much the Schema.org markup matters. To answer such questions, we must acquire a deeper understanding of the linked data cloud. During the next three years, we will collaborate with the Arlitsch team, who are experts in search engine optimization for library resources (Arlitsch and OBrien 2013). With financial support from a grant awarded to Montana State University by the Institute of Museum and Library Studies in September 2014, we are developing and testing models to increase the Web visibility of university-managed institutional repositories, documenting the steps required for achieving success.
5.3.3 Environmental Challenges
This book has described OCLC’s effort to publish linked data on the Web. But how do OCLC’s projects and others published by the library community contribute to the Semantic Web? To find out, Smith-Yoshimura (2014a) conducted an online survey of publishers and consumers of linked data in the library community. The survey elicited 72 respondents, 51 of whom are linked data publishers; nearly every project discussed in this book is represented, plus many others. In decreasing order of RDF triple count, the largest datasets being consumed by the survey participants are WorldCat, WorldCat Works, Europeana, and The European Library (TEL 2014b), a Web portal that provides access to the collections of 48 national and research libraries in Europe. The most commonly used data standards for publication are those discussed in this book: SKOS, FOAF, Dublin Core, Dublin Core Terms, and Schema.org. The pattern of linked data consumption among the survey participants is summarized in Table 5.1. Third-party datasets consumed by OCLC’s linked data projects are highlighted in red. The tabulated survey responses are also represented as a bar graph in Figure 5.4.

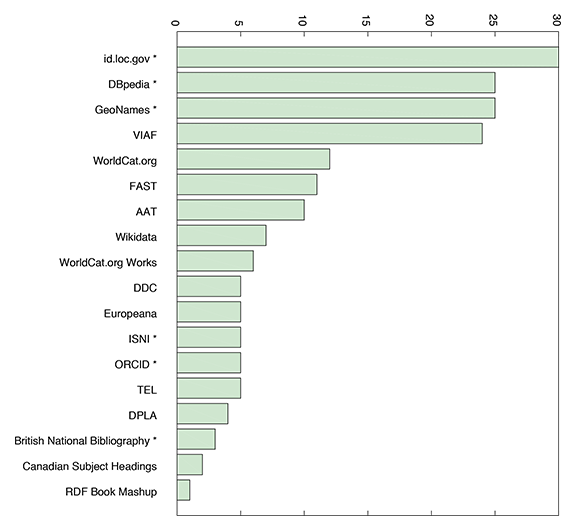
The datasets mentioned in Table 5.1 and Figure 5.4 were listed in the survey questions, but participants were also invited to supply the names of other resources they are consuming. The long list of responses includes http://data.bnf.fr from the Bibliothèque nationale de France (BNF 2014), the Linked Data Service from the Deutsche Nationalbibliothek (DNB 2015), and the General Multilingual Environmental Thesaurus (GMET 2014). A spreadsheet containing the complete set of raw responses is also Web-accessible (OCLC 2014b).
Since the survey results became available just as this book was going to production, they capture the same moment in time, complementing the insider’s perspective documented in the previous pages with a glimpse of the broader landscape. The survey is not a scientific sample, and we have to interpret the results with caution, but it sparks impressions that can be validated by other lines of inquiry. For example, the interest in linked data by the library community is international. The cloud is still organizing itself, but it is centered on http://id.loc.gov and VIAF, the oldest datasets published by the library community. DBpedia and GeoNames also figure prominently, anchoring library linked data to the center of the iconic Linked Open Data cloud for the broader Web (Cyganiac and Jensch 2014), mentioned in the opening pages of Chapter 1. Many cutting-edge projects are still emerging—such as WorldCat Works; services that assign persistent identifiers to researchers, such as ISNI (ISNI 2014) and ORCID (ORCID 2015); and the Digital Public Library of America (DPLA 2014), the first national digital library of the United States, whose contents are freely accessible. Even more nascent are the linked data resources named by the survey participants, many of which were not published by libraries but by organizations that serve individual areas of study. When this survey is repeated later in 2015, we expect the landscape to be more populated and interconnected, replicating the trajectory of change observed in the LOD cloud diagram.
The survey also sheds light on the impact of OCLC’s linked data projects, whose datasets are among the oldest, largest, and most widely consumed. But a future imperative for OCLC is to create more connections among the resources published by libraries and affiliated communities, starting with the initiatives described in this chapter. As members of an international community, we share the same aspirations: to demonstrate that library resource descriptions can be promoted from the web of documents to the Web of Data, and to use the new architecture to broaden the reach of libraries. If we succeed, we will have realized the vision of integrating libraries with the broader Web, where they can connect to users in their native environment and deliver the resources they request at no cost. This act of fulfillment is a reminder that the public mission of libraries can be advanced through a better integration with the commercial interests that populate the Semantic Web. But the service offered by libraries is unique.