Library Linked Data in the Cloud
OCLC's Experiments with New Models of Resource Description

Authors
Jean Godby, Ph.D.
Senior Research Scientist
Shenghui Wang, Ph.D.
Research Scientist
Jeff Mixter
Sr. Software Engineer
Chapter 4: Entity Identification Through Text Mining
- 4.1 The Need
- 4.1.1 Text Mining Defined
- 4.1.2 Associating Text with a URI
- 4.2 Recognizing Key Entities
- 4.2.1 Labeled Names
- 4.2.2 Names in Semi-structured Text
- 4.2.3 Names in Unstructured Text
- 4.3 Concept Matching
- 4.3.1 Creating Alignments
- 4.3.2 Linked Library Vocabularies
- 4.4 Clustering
- 4.5 Chapter Summary
4.1 The Need
Throughout this book, we have emphasized two stubborn facts about legacy library data: it consists primarily of human-readable text that is difficult for machines to process, and the reliable structured data that served as input to the first-generation linked data models is severely restricted. Put in more colloquial terms, library linked data models have been built by picking low-hanging fruit, primarily from the controlled access fields of MARC bibliographic records and their corresponding associations with library authority files. This has been a productive strategy, yielding globally unique URIs for four of the six key entities—people, places, organizations, and concepts—that frame the scope of our investigation, as well as the first drafts of authoritative hubs derived from library authority files and a concrete list of tasks for achieving greater maturity. But Chapter 3 showed the need to go beyond controlled-access fields to assemble the evidence required for building authoritative hubs of creative works. The need is especially acute because the algorithms that produce the outputs required by the linked data paradigm are built on older processes designed to identify semantically important similarities or to eliminate errors and redundancies in conventionally designed aggregations of library resource descriptions—problems that must also be addressed in the management of WorldCat cataloging data as well as other collections such as Europeana (2014) and the Digital Public Library of America (DPLA 2014). But these processes are reaching their upper limits, and we are now evaluating the algorithms developed by text mining researchers.
4.1.1 Text Mining Defined
Rooted in computational linguistics and information retrieval (Hearst 1999), text mining—also known as intelligent text analysis, text data mining, or knowledge-discovery in text—refers to the process of discovering and capturing semantic information and knowledge from large collections of unstructured text. The ultimate goal is to enable knowledge discovery via either textual or visual access for use in a wide range of significant applications. It is different from data mining, which is more about discovering patterns in numeric or structured data stored in databases. Though similar techniques are sometimes used, text mining has many additional constraints caused by the unstructured nature of the textual content and the use of natural languages. It uses techniques from information retrieval, information extraction, and natural language processing and connects them with the algorithms and methods of knowledge discovery in databases, data mining, machine learning and statistics.
4.1.2 Associating Text with a URI
The data problems that we address using text mining algorithms are both easier and more challenging to solve than those encountered in unstructured free text, the typical input to text mining algorithms that have been studied in the computer science and computational linguistics research communities.
On the one hand, the problems in the domain of library resource management are easier to solve because library metadata is semi-structured. For example, entity recognition algorithms have relatively little work to do in a string such as ‘Publisher: Washington, DC; Potomac Books, 2005’ because the text is sparse, the punctuation identifies important phrase boundaries, and the string is already labeled with the name of an important relationship—namely, ‘Publisher’, from which a software process can infer that the name of a person or organization can be found somewhere in the rest of the text. Moreover, WorldCat, like most aggregations of library resource descriptions, contains a large amount of highly curated, structured data that can already be correctly associated through an algorithmic process with the entities and relationships in a linked data model, as we have argued. This substrate of clean data can be used to bootstrap information discovery in data elsewhere in WorldCat that is much more difficult to process.
But our needs are demanding because the outputs of text mining algorithms are useful only if they meet high standards for accuracy in a large-scale production environment. As we follow Coyle’s prescription (2012) for preparing library resource descriptions for input into a linked data model of library resource description, we are ascending a staircase, moving from free text to normalized text to data associated with dereferenceable URIs. If this information can be correctly extracted, labeled, linked with named properties, and aggregated with third-party resources, text mining algorithms can populate our model and be used to discover previously undetected patterns, maps of connections, and trends. But these algorithms eventually produce diminishing returns when they operate on data that is too sparse and full of errors.
The unifying goal of the research projects described in this chapter is to extract data from the text in OCLC’s collections and advance it toward a fully articulated linked data representation. In the sections below, we identify three important needs by the work presented in previous chapters and show how the most relevant text mining sub-disciplines can be used to address them.
4.2 Recognizing Key Entities
The discussion can begin by considering the MARC record shown in Figure 4.1, which is a complete excerpt for the coded data fields numbered below 245. This is a description of a book about local history compiled by the Little River County Historical Society in Arkansas. It is represented by two records available from WorldCat—one with the publisher named ‘Heritage House Publishers’ and the other shown below, which lists the publisher as ‘Heritage House Pub.’ Copies of books matching both descriptions are available from libraries in Fort Wayne, Indiana; Independence, Missouri; and Little Rock, Pine Bluff, and Bentonville, Arkansas.

The RDF/Turtle representation published on WorldCat.org is shown in Figure 4.2. Note that only two of the RDF objects are represented as URIs. Two schema:about statements correctly mention the identifiers for ‘Arkansas—Little River County’ and ‘Arkansas.’

But most of the other objects referenced in the RDF/Turtle statements are represented as strings, including several key entities, such as the name of the publisher and the name of the corporate author ‘Little River County Historical Society.’ Several subject headings also lack URIs, such as ‘Ashdown (Ark.)’ and ‘Little River County (Ark.)’ which to a human reader appears to refer to the same place as the heading associated with the FAST URI http://id.worldcat.org/fast/1217655 (‘Arkansas—Little River County’). In addition, the description mentions other entities, such as the related work ‘History of Little River County,’ the organization named ‘Little River News,’ and ‘Judge John C. Finley III,’ who contributed to the history of Ashdown described in the MARC record.
The goal of several research projects now being conducted at OCLC is to promote strings to entities by applying text mining algorithms to MARC records and other library resource descriptions represented in text-heavy legacy formats. Schematically, Figure 4.3 represents the population of nameable entities in a large aggregated database of library resource descriptions such as WorldCat. The concentric circles can be read as slices of a three-dimensional solid representing increasingly larger segments of an information space containing entities with potentially assignable identifiers.

Chapter 2 showed that an identifier is assignable only if the string appears in a controlled MARC field and the controlling authority has been modeled as linked data, which means that identifiers for people, organizations, concepts, and topics have effectively been established by a long process initiated by the spadework of human catalogers. They form the smallest segment on the top of Figure 4.3.
The second segment represents the population of entities that have already been labeled by catalogers as persons, places, organizations, or concepts, but are not associated with identifiers, such as the publisher (‘Heritage House Pub.’), the place of publication (‘Marceline, MO’), and the contributor (‘Little River County Historical Society, Ark.’) of the example shown in Figure 4.1. Most importantly, this subset of entities have key relationships to the creative work, such as publisher, author, contributor, and ‘aboutness.’ In many cases, these entities can be associated with identifiers already defined in library authority files or third-party resources such as DBpedia or Geonames. And once these strings are promoted to entities, further improvements to the description should be possible. For example, it will be obvious that the description contains two mentions of the place with the name ‘Little River County (Ark.)’ in the list of schema:about statements, one of which could be eliminated. It is therefore critical for the prospects of the large-scale conversion of WorldCat catalog records to linked data that entity-recognition algorithms consider an expanded body of evidence because less robust methods are already nearing their upper limits.
In Section 4.2.2, we will discuss the third segment: free text that is highly structured or stylized, to which named-entity extraction algorithms can be productively applied. Some of the extracted entities have assignable identifiers, but many do not. The final segment represents unstructured free text such as texts marked up with schema:description in Figure 4.2, which is the typical input to natural language processing algorithms studied by academic computer science or information science researchers. Since here the entity extraction and identity resolution tasks are the most challenging, we will address them only after some of the more tractable problems have been solved.
The text mining solution most relevant here is named entity recognition, or NER, a well-studied set of software processes developed in the academic computing community for identifying atomic elements in a string and labeling them with the names of predefined categories for people, places, organizations, and concepts (Godby et al. 2010). But despite the obvious overlap between the names of the key entities in OCLC’s linked data model and those labeled by NER tools, the fit is only approximate. As the examples below demonstrate, the most important requirement for success in the string-to-thing promotion task, at least as we have defined it, is the presence of relevant machine-processable data elsewhere in the record, such as coded or controlled data and previously assigned identifiers. A process involving NER may exploit this information, but it is only one tool among many that is useful for addressing this problem.
4.2.1 Labeled Names
As mentioned, these names have already been labeled by human catalogers but have not been subjected to authority control and can only be mapped to string values in the current Schema.org markup published on WorldCat.org. In words that might be used by an natural language processing researcher, the entity has been extracted but not disambiguated. But the locations of these names in a MARC record imply that they represent key entities with machine-processable relationships to creative works. At the very least, this information can be used to construct RDF triples represented by the pseudo-code <‘A History of Ashdown’> <Publisher> <‘Heritage House Publishers’>, to use data from the record cited above.
4.2.1.1 Publishers. Figure 4.4 contains a truncated MARC record accessible from WorldCat that describes Clean Your Room, Harvey Moon!—a first-grade primer published in New York, presumably for an audience of American schoolchildren. As in previously discussed examples, Pat Cummings, the primary author, is listed in the authority-controlled 100 field and is thus associated with a VIAF identifier in the corresponding Schema.org markup. But the 260 field mentions the names of two additional entities—‘New York’ and ‘Macmillan/McGraw-Hill School Pub. Co.’—which are also important in the domain of library resource description but have not been subjected to authority control. The semantics of the MARC record identify the first as the name of a place, which is related to the creative work with the OCLC-defined property library:placeOfPublication, which is slated to be redefined in BiblioGraph. The second is the name of an organization, which is related to the creative work with the property schema:publisher. This markup is visible in the RDF statements accessible from WorldCat.org, as we have noted in the discussion of similar examples in earlier chapters.

Special processing is required to promote the two strings mentioned in the MARC 260 field to identifiers, despite the fact that URIs are available for both entities: in VIAF for the publisher, and in FAST and LCSH for the place of publication. To associate the names with the URIs, it is necessary to devise a process that matches the two strings to a skos:prefLabel or skos:altLabel listed in the corresponding SKOS-encoded authority-file description of the concept, a format discussed in Chapter 2. But since the two strings do not appear in the MARC description in an authority-controlled field, they may vary from the authoritative source because of spelling or transcription errors or differences in local descriptive practice. The association of the string ‘New York’ with the correct identifier might appear relatively straightforward because this well-known geographic name can be interpreted by a human reader of the MARC record shown in Figure 4.4 as the name of the city in the state of New York. Real-world knowledge fills in the gap that ‘place of publication’ in a bibliographic description usually involves the mention of a major international city where publication houses are located, such as New York, New York; London, England; or Tokyo, Japan; but not London, Ohio, a farming village in central Ohio. But the knowledge was not available to the machine process that produced the microdata for WorldCat and ‘New York’ is marked up as a string instead of an entity.
Unfortunately, no URI was assigned to the publisher name at all because such names are typically not controlled in library authority files. Publishing companies are so frequently reorganized that considerable human effort is required to maintain a resource that tracks the history of organizations such as Macmillan and McGraw-Hill, which were once separate companies but have recently been merged to form a single company with the name ‘Macmillan/McGraw-Hill’ (Connaway and Dickey 2011). But even if this resource is created, it is difficult to establish the correct form of the name because the publishing industry does not maintain its own authority files.
Nevertheless, the presence of the 710 field in the above figure promises to solve part of the problem. Perhaps because elementary-school primers often have corporate authors, a string containing the words ‘Macmillan/McGraw-Hill’ is available as a controlled name, reflecting the fact that this company has been attested as a creator or contributor to a creative work. Most publishers do not receive this treatment because they do not typically act as authors. But if present, the 710 field permits the inference that the string has been defined in the Library of Congress Name Authority File, from which a VIAF identifier can be algorithmically derived, while the 260 field supplements the description with the fact that this corporate entity has a ‘publisher’ relationship to the creative work. A fuzzy matching algorithm applied to the MARC record would be required to associate the strings appearing in the 260 and 710 fields. This heuristic would have a reasonable chance of being successful, but to ensure that the name is correct, timely, and close to the form of the name that is prevalent in the publisher supply chain, more robust text mining algorithms would be required to build an authoritative resource of publisher names or match them with existing identifiers registered with ISNI (2014). OCLC researchers are currently investigating this possibility.
Translators
In the Multilingual WorldCat study first mentioned in Chapter 3 (Gatenby 2013), one important task is the identification of translators in MARC bibliographic records. If one book is a translation of another, the cataloger should indicate the name of the translator in the $a subfield and the ‘translator’ role in the $e (‘Relator Term’) or $4 (‘Relator Code’) subfields of the MARC 700 field. When this data is present, it can be transformed directly into linked data, which was done for more than 65,000 records in the ‘data.bnf.fr’ project (Simon et al. 2013). But in WorldCat catalog data, the subfields $e and $4 for the 100/700 fields are sparsely populated. Only 45 million (14%) records in WorldCat have been cataloged with $e or $4, and only a subset of these, or 1.6 million records, make explicit mention of translators. Thus if we only rely on machine-processable metadata, most of the translators would be missed, in part because cataloging rules do not require authority control for translators.


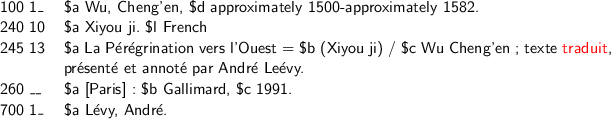
A more careful look at the metadata reveals that the translators are often indicated in the free-text 245$c (‘Statement of Responsibility’) field, as shown in Figures 4.5, 4.6, and 4.7. Human readers can easily detect that ‘Li shu zhen,’ ‘H. Bencraft Joly,’ and ‘Leé vy, André ’ are translators, indicated by ‘yi’ (and ‘譯’ meaning ‘translate’ in Chinese in the 800-245$c field), ‘translated by’ and ‘traduit’ (‘translated’ in French) in the free-text 245$c field, highlighted in red. Though these names are cataloged in the authority-controlled 700 field, their relationships to the corresponding Works are unknown. As a result, these names can be labeled only as schema:Contributor instead of a more precise property. Since their appearance in the 700 fields permits them to be labeled as personal names, they could be assigned VIAF identifiers with high confidence,1 or they could be added into VIAF through a semi-automated process.
As in the case of publisher names, a text mining approach could be applied here to match the personal names in the controlled 700 field with the names in the free text of the 245$c field, with the help of a list of words that indicate translators in different languages and writing systems such as ‘translated by,’ ‘譯’ or ‘译’ (Chinese), ‘traduit’ (French), or ‘traducción’ (Spanish). In this way, more translator entities could be detected. Our current text mining software has successfully detected translators for an extra 2.7 million records.
However, matching these names requires a more complex process than simple string matching. The names occurring in the 245$c field often have different forms from those in the 700 field—for example, ‘H. Bencraft Joly’ vs. ‘Joly, H. Bencraft.’ For non-Latin scripts, such as Chinese, Japanese, and Korean names, matching based on their romanized characters is not reliable; instead, the matching needs to be done on characters in their original scripts cataloged in the 880 fields (see Figure 4.5). Furthermore, translators could be introduced in different ways in free text, such as the example shown in Figure 4.7. Matching the correct name string and identifying its role is therefore not as straightforward as it appeared in the beginning, and the task of matching these name strings with the correct names in VIAF is an additional challenge.
More often than not, the name of a translator is never explicitly cataloged in the controlled 700 field and is only mentioned in the free-text 245$c field. These names belong to the bottom segment in Figure 4.3 and require a more sophisticated extraction process from unstructured text. But the data obtained from the matching of the 700 and corresponding 245$c fields can be used as a training set for an entity-extraction classifier to extract translators in the 245$c field. However, because of the complexity and variation observed in natural-language free text, a completely automated solution to this problem is unlikely, and a hybrid approach that combines machine learning with crowdsourcing by librarians or domain experts is probably more practical.
4.2.2 Names in Semi-structured Text
As shown in previous chapters, MARC records that contain relatively little unstructured text are easily rendered as RDF triples. But some cataloging communities make extensive use of highly formatted notes featuring many entities and relationships. We are exploring the possibility that this text could be promoted to a more machine-processable format. Figure 4.8 shows an excerpt of a MARC record available from WorldCat describing a film about Rodgers and Hammerstein, the team that created many famous Broadway musicals, including The King and I, Oklahoma!, and The Sound of Music.

A human reader can discern that the MARC 245 field mentions both important names in the ‘Title’ string. But the 600 fields supplied by the cataloger do the real work of establishing the connection with the real-world entities. The semantics of the MARC 600 field permit the inference that the creative work with the title Richard Rodgers and Oscar Hammerstein, II is indeed ‘about’ two unique individuals whose names are controlled in the Library of Congress Name Authority file. As we have seen, the presence of a controlled access point in a MARC description also enables the assignment of a VIAF identifier. Thus, the strings ‘Richard Rodgers’ and ‘Oscar Hammerstein’ have been identified and disambiguated through the normal course of cataloging, and have been associated with resolvable identifiers through mature linked data models of library authority files.
The MARC 508 field is a formatted note containing names of other people and the roles they performed in the creation and production of the film. Though the data in this field is a long string whose contents are accessible in WorldCat only through keyword indexing, a human reader can easily parse the names and roles into the list shown below the excerpted record. This is also the output that could be obtained from an named-entity extractor enhanced with the ability to identify the names of roles in this limited context. Since the information shown in the MARC 508 field in Figure 4.8 is both valuable and within the scope of what named-entity extractors enhanced with heuristics that identify the names of roles in this limited context could compute with reasonable accuracy, we are investigating the feasibility of mining all 6.3 million records in WorldCat that describe films or recordings of theatrical and musical performances to extract names and roles from formatted MARC notes fields. Using information available elsewhere in the record, an algorithm would transform the data to RDF triples such as <Richard Hall> <illustrator> <Richard Rodgers and Oscar Hammerstein, II>. Roles such as ‘illustrator’ or ‘director’ are valuable for producing richer RDF statements, as they introduce more real-world relations between people and creative works.
Current results on a small pilot study show accuracy rates nearing 88% for the extraction of names and 75% for roles. If the results can be replicated on a larger sample, this project promises to yield a large and heretofore unexplored network of names and relationships in the domain of musical and theatrical performance contributed by multiple communities of specialized library catalogers. But several challenges must be overcome. First, notes fields are still free text, even if they are highly formatted, and not all of the 508 fields attested in WorldCat conform to easily discovered patterns. Second, a full resolution of this problem awaits results from the research on multilingual bibliographic descriptions discussed above, partly because some of the text is not in English and partly because VIAF descriptions will have to be created for some of the extracted names using the same conventions. Finally, an extra interpretation step is required to transform the names of roles such as ‘script’ discovered in the text to a more precise property of agency, such as ‘script writer.’ Nevertheless, in a corpus as large as WorldCat, even a subset of correctly parsed data contains information that can be channeled to upstream processes, and we are devising algorithms that can identify these results automatically.
4.2.3 Names in Unstructured Text
Though it is outside the scope of our current work, the processing of names found in unstructured text, depicted schematically as the lowest segment of Figure 4.3, is a potentially rewarding task because it promises to reveal even richer knowledge from the legacy data contributed by library catalogers from all over the world. For example, the short summary shown in Figure 4.1 connects at least two published books and their authors, a local organization, and an event involving a judge researching local history. This is an interesting piece of real-world knowledge hidden in a single bibliographic record. Though current state-of-the-art NER tools cannot extract the named entities with the precision required for library resource description, such knowledge could be extracted with the help of local history enthusiasts or other specialized communities, a strategy that is already being pursued in the library community. For example, the ‘Linked Jazz’ project sponsored by the New York Public Library has successfully engaged a community of popular jazz enthusiasts to annotate the names and relationships among artists, performers, and musical works in a corpus of digitized documents, which have been converted to RDF triples (Pattuelli et al. 2013).
4.3 Concept Matching
Persons, organizations, and places are key entities in the initial draft of OCLC’s linked data model of resources managed by libraries, but so are concepts or subjects. Libraries use controlled knowledge organization systems (KOSs), such as thesauri or subject heading lists (SHLs), to describe the subjects of the records in their collections. KOSs are typically stored as Name Authority records in MARC 21 name authority files, as we discussed in Chapter 2 (Section 2.2.1). Following the standard set by LCSH, library standards experts have modeled many name authority files in SKOS (see Section 2.2.2), where a skos:Concept is a curated string with an implied meaning defined by its position in a thesaurus. A richer set of links among the concepts defined in these authority files would improve access to individual resource descriptions and realize part of the vision that motivates the development of linked data: greater visibility for libraries in the global web of data.
Concept matching also solves more immediate problems. When bibliographic records are aggregated, de-duplicated, and merged into aggregations such as the WorldCat database, many records end up with subjects from multiple authority files, often expressed in different languages. Figure 4.9 shows an example. The topical subjects in three different colors are from English, Dutch, and French thesauri, respectively. The English subjects are from LCSH and refer to concepts defined in an authority file that has already been modeled as linked data. However, the Dutch and French subjects are defined in GTT and Répertoire de vedettes-matière, which are still represented in legacy record formats, and are therefore represented only as strings, not URIs, in the RDF markup published on WorldCat.org. But a more careful look at these fields reveals that the French subjects are literal translations of the English ones, consisting primarily of cognates that are obvious even to readers who do not know French. The Dutch subjects are also synonymous to the English concepts to readers who understand Dutch: ‘Letterkunde’ (Literature), ‘Engles’ (English), ‘Godsdienst’ (Religion), and ‘Victoriaanse tijd’ (Victorian era). None of the corresponding terms are connected by machine-processable assertions of relatedness.

If the concepts were mapped, the description could be customized to the user’s language of choice and the display would appear less cluttered because English users would see only the heading ‘Religion in literature,’ not the apparently redundant French heading ‘Religion et littératur.’ As an added benefit, users who issue subject searches could retrieve results in a different language from that of their query, overcoming barriers to access that occur when a library collection is described in the local language regardless of the language of the content. For example, consider the monolingual English-speaking user living in Paris who is interested in books about sprinting. Since books held by the Bibliothèque nationale de France are most likely described with a French thesaurus, books about sprinting would be assigned the subject heading ‘Course de vitesse’ (‘sprinting’ in French), and the user’s query ‘Sprinting’ would be unsuccessful even if the collection has an English-language book on this topic. But the request could be fulfilled if the French thesaurus were modeled in SKOS with an owl:sameAs or skos:closeMatch property that links the French skos:Concept to the corresponding English one, as shown in Figure 4.10. An automated process could then follow such links to retrieve books with the same or closely matched subjects.

As we will show below, an aggregation of metadata about creative works such as WorldCat can be consulted as a corpus by an automated process to obtain evidence for the owl:sameAs or skos:closeMatch relationships, which can then be algorithmically applied to the corresponding authority files.
4.3.1 Creating Alignments
While much manual effort has been undertaken to create alignments, or sets of mappings (Landry 2009), a crucial problem with this approach is its enormous cost. Some reports mention that around 90 terms may be matched per day by a skilled information professional dealing with concepts in the same language (Will 2001); but in a multilingual context, the rate is lower. Automated matching methods are clearly necessary.
Semantic Web research is identifying the similarities and differences between the task of matching controlled vocabularies and the more generic task of ontology matching (Shvaiko and Euzenat 2013). The vocabularies used in libraries or cultural heritage institutions are usually large and have been developed over the course of decades to serve the goals of storing, finding, and accessing a specific collection of objects. The semantics of thesauri differ from the semantics of ontologies: in a thesaurus, real-world objects are modeled as concepts, and may not be referenced directly. This is the same distinction we identified in Chapter 2, where we argued that a skos:Concept describing ‘Mark Twain’ does not refer to Mark Twain the person unless the description also contains a foaf:focus property. Therefore, thesaurus-matching methods are different from those used for ontology matching, but both involve text mining algorithms.
On the one hand, various linguistic resources, especially multilingual ones, help to reveal the real semantics under different lexical/syntactic forms or labels in different languages, so that lexical matching could detect potential mappings, such as ‘Sprinting’ (LCSH) – ‘Course de vitesse’ (Rameau) – ‘Kurzstreckenlauf’ (SWD). Recently, multilingual knowledge bases such as DBpedia have also been used as background knowledge for matching concepts from different ontologies. The multilingual links within these knowledge bases play a broker’s role in connecting concepts with labels in different languages.
On the other hand, library resource descriptions can be treated as instance data that can be used to calculate the similarity of concepts in terms of practical usage. For example, the Dutch concept ‘Glomerulopathie’ and the FAST concept ‘Kidney glomerulus--Diseases’ are used to describe similar sets of books in WorldCat catalog data, which reflects their high similarity or relatedness. Such mappings are difficult to obtain from linguistic resources alone (Isaac et al. 2007). But machine-learning techniques reveal the textual similarity between books (as represented by the text of titles, abstracts, and keywords) and the relatedness of their subjects (Wang, Englebienne, and Schlobach 2008). Given the size of the WorldCat database, text mining algorithms could produce more valuable instance-based mappings that have been proven useful in book re-indexing applications (Wang et al. 2012), even in a multilingual context (Wang et al. 2009). In fact, instance-based matching techniques can be useful to detect mappings which are not strict equivalence links, such as the skos:broadMatch and skos:relatedMatch relations from the SKOS model, which are derived from thesaurus standards.
The matching methods described here, especially instance-based ones, are actually generic enough to be applied to other problems involving entity identification. Anticipating the discussion in the next section, Table 4.1 shows excerpts from descriptions available from WorldCat for the World War II memoir American Guerrilla, which a human reader might perceive as redundant. Failure analysis reveals that records that might be collapsed into a single description are maintained as distinct descriptions because some of them cite Brassey’s as the publisher, while others cite Potomac Books. But if an instance-based mapping method was applied in this context to reveal that the two publisher names appear in essentially the same contexts, it would be possible to infer, correctly, that these publishers are related because Brassey’s is an imprint of Potomac Books. Similarly, if two author name strings are associated with similar publications (in terms of subjects, word usages, co-authors, etc.), it is likely that these two names refer to the same person. Even if the final decisions still need human intervention, finding potentially linked candidates could reduce the problem space enormously.
From a broader perspective, the same method could be used to identify similar entities such as journals and journal article authors. Starting from the simple hypothesis that similar journals publish similar articles, we have measured similarities among 35 thousand journals using metadata associated with 67 million articles that have been published in them (Koopman and Wang 2014). The article metadata, derived primarily from the title and abstract fields in MARC rcords, is aggregated per journal and the similarity is calculated from aggregated text. This method can group similar journals in certain research fields and, more interestingly, can identify ‘broker’ journals connecting multiple disciplines. These algorithms can also associate the articles or monographs written by the same author, even if the descriptions have no URIs or authority-controlled fields because an author's linguistic signature is measurably distinctive, especially in works on the same topic. As a result, the distinction between John Kennedy the biologist and John Kennedy the historian and 35th president is discoverable in the WorldCat database when it is treated as a large corpus. Thus the investigation that started as a variant of instance-based concept matching has deep implications for the identification of entities and relationships in library metadata, and is especially rewarding when the quality of the data is uneven.
4.3.2 Linked Library Vocabularies
Once vocabularies are mapped, a user needs to use only one concept label to retrieve all records described by concepts with the same semantics, under either monolingual or multilingual circumstances. For example, when a user searches for books with the subject ‘Course de vitesse,’ books with the subject of ‘Sprinting’ or ‘Kurzstreckenlauf’ should also be returned. This is only possible when concepts from different thesauri are properly linked. As shown in Figure 4.10, via a set of skos:closeMatch properties, this Rameau2 concept is linked to three SWD3 concepts, one LCSH concept, and one Dewey code.
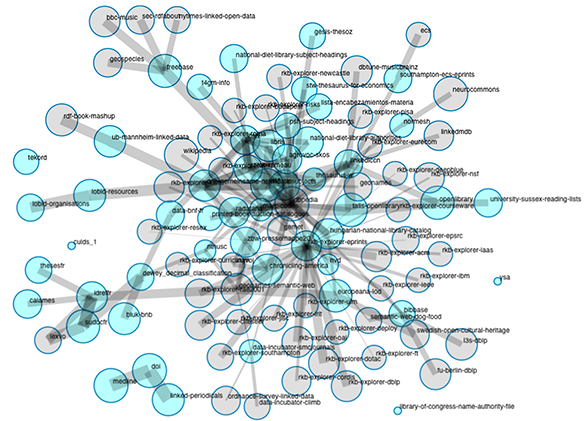
When vocabularies and authority files maintained by libraries are represented in a more machine-processable format with machine-understandable semantics, they are ready for wider exposure. Figure 4.11 depicts an example of linked library vocabularies published by the W3C Library Linked Data Incubator Group in 2011 (Isaac et al. 2011). The connections among these vocabularies are generated automatically—in some cases, to datasets outside the Library domain, such as DBpedia and Freebase. When such semantic links have been defined, legacy data curated by libraries can be integrated into the web of data, where it can be leveraged to support the next generation of Semantic Web applications. In return, the work of linguists and lexicographers in the broader community would be available to enrich the Concept entities defined in the library community.
4.4 Clustering
Document clustering is a fundamental task of text mining, through which more efficient organization, navigation, summarization, and retrieval of documents may be achieved. Automatic clustering is especially important for large-scale aggregations containing many records describing similar or related content. If such records are not grouped in some meaningful way, the information seeker is confronted with results that appear to be redundant or messy.
Clusters may reveal duplicate documents or important entities and relationships, such as those defined in the model of creative works discussed in Chapter 3. Of these, duplicates are most visible to the reader, seemingly the most straightforward to address, but the most difficult to resolve. OCLC’s installed production processes remove identical records by checking similarities among highly reliable numeric or controlled strings such as the ISBN, author, title, edition statement, and physical description. But the multiple versions of American Guerrilla elude this process because the ten descriptions available from WorldCat are all slightly different, as the descriptions in Table 4.1 reveal.4
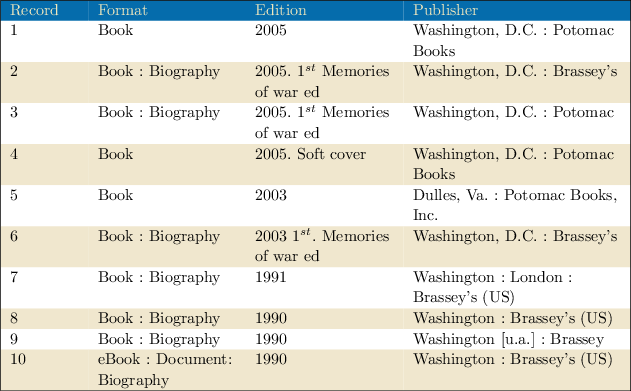
The data shown in Table 4.1 represents a failure, a success, and a set of goals for further research. It can be interpreted as a failure because records 1 and 3 are so similar that a more sophisticated string-matching algorithm might have been able to eliminate one of them as a duplicate. Such a result could be visible in a future version of WorldCat.org because OCLC’s duplicate-detection algorithms are constantly being revised. But the data also represents a success because it is the result of the clustering algorithm discussed in Chapter 3, which identifies Manifestations of the same Work. Of course, future versions of the WorldCat.org user interface need to be more explicit about the common characteristics of the Work entity that underlies this list—that it is a memoir published by a survivor of a Japanese internment camp in World War II and is available in the multiple formats shown here. Finally, the descriptions listed in Table 4.1 show the need for more research on the problem of identifying real-world entities and relationships in noisy textual data. For example, the knowledge that Brassey’s is an imprint of Potomac Books would make it possible to label records 2 and 3 as duplicates because they point to the same object. Moreover, records 9 and 10 have exactly the same content because 10 is a digitized version of 9.
Sorting out these issues is a major task, but clustering algorithms provide a useful start. Chapter 3 showed that clustering algorithms are already being used in many OCLC projects to identify related groups of creative works. But the inputs are restricted to highly reliable structured data, such as names, titles, and subject headings, because the processes must operate fully automatically in a production environment, which has little tolerance for error and places a premium on computational efficiency. As a research project, we are also investigating what can be learned from clustering algorithms that measure similiarity on the complete text of a resource description and are evaluated by human judgment with the goal of creating a dignostic tool for knowledge discovery. This work focuses on relationships among Items, providing input to a model and the design of a process that will eventually be able to run without human supervision.
Our analysis has shown that, depending on the data attributes and the (dis)similarity measures used by the clustering algorithm, clusters may reveal the presence of close or exact textual duplicates, identical real-world referents, or real-world referents that are connected to one another in some fashion. From a broader semantic perspective, digital objects could be connected based on many different dimensions, forming clusters around similar periods of time, geo-locations, subjects, people, events, etc. For example, Figure 4.12 depicts a group of images that could be grouped together by different criteria—as pictures of the same real-world person, as objects curated in the same collections, or as people with the same job title. Other use cases might require the exploration of a cluster that contains pictures of the people who share the same office or go to the same school. Once exposed as linked data, these clusters of different granularities could enable users to explore large-scale aggregations in a much more flexible and exploratory way.

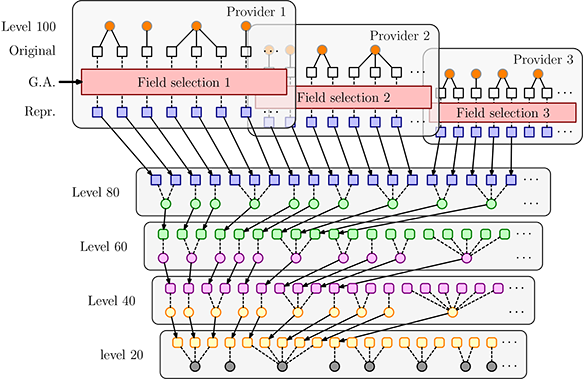
This result was demonstrated in our experimental clustering of an aggregated collection of metadata about cultural heritage materials (Wang et al. 2013). Collaborating with a development team responsible for the publication of Europeana, we were interested in identifying related cultural heritage objects (CHOs) at different levels of similarity, which potentially reflect different semantic relations among them. As depicted in Figure 4.13, we provided clusters at five similarity levels, with level 100 giving near-duplicates and level 20 the most vaguely connected objects. A user could thus explore the collections to find CHOs with different levels of relatedness. A more detailed study reveals the typology of groupings, which cover a broad range of relations defined in the Europeana Data Model (Europeana 2014), such as same objects/duplicate records, views of the same object, parts of an object, derivative works, collections, and thematic groupings. This finding is a good match with the multiple facets of CHOs, even if the similarity used in the clustering is purely based on textual data. However, this approach could not benefit from the semantic information embedded in the data itself. For example, if we treat the content of the dc:creator field as person name string instead of simple text, we could calculate the similarity of CHOs based on their creators. The same goes for many other metadata fields, such as dc:subject, dc:publisher, etc. For the free-text fields, such as dc:title and dc:description, a good information extraction process needs to be applied first to extract valuable semantic information, from which the clustering process could produce more sensible semantic clusters along different dimensions.
In the future, large-scale digital libraries will host more and more heterogeneous digital objects. For example, tens of millions of digital objects are already automatically ingested into WorldCat through the Digital Collection Gateway (OCLC 2014c). Thus it is important to apply clustering algorithms and other semantic technologies to discover meaningful relationships among digital objects that can populate richer data models. These efforts are mutually reinforcing and a subject of emerging work at OCLC, which we will mention briefly in Chapter 5.
4.5 Chapter Summary
This chapter has surveyed some of the most promising text mining algorithms that are already being used to promote text to machine-processable data in library resource descriptions. These results are valuable in their own right, but they also have cascading effects that feed into the process flow for generating the empirical evidence for OCLC’s linked data models. Cleaner descriptions of creative works improve the performance of the Works cluster algorithms described in Chapter 3. Evidence gathered along the way can also be applied to the improvement of authoritative hubs for other entities that are mentioned in bibliographic data maintained by libraries. In sum, what we have described here is part of the pipeline for iterative improvement of OCLC’s bibliographic and authority data; or more precisely in the linked data architecture, the repositories for authoritative information about the entities required for library resource descriptions that are earmarked for publication on the broader Web. Text mining algorithms are a key component and will become more and more important as these resources continue to grow.