Library Linked Data in the Cloud
OCLC's Experiments with New Models of Resource Description

Authors
Jean Godby, Ph.D.
Senior Research Scientist
Shenghui Wang, Ph.D.
Research Scientist
Jeff Mixter
Sr. Software Engineer
Chapter 2 : Modeling Library Authority Files
- 2.1 Strings and Things
- 2.2 From Authority Records to RDF Triples
- 2.2.6 The Dewey Decimal Classification
- 2.2.7 Summary: First-Generation RDF Models of Library Authority Files
2.1 Strings and Things
In a keynote speech to a workshop associated with the 2012 LODLAM conference (International Linked Open Data in Libraries, Archives, and Museums), Mia Ridge, chair of the Museums Computer Group and a member of the Executive Council for the Association for Computers in the Humanities, gives a straightforward explanation of the ‘Things, not Strings’ problem, and hints at a solution:
“Computers are dumb. Well, they’re not as smart as us, anyway. Computers think in strings (and numbers) where people think in ‘things.’ If I say ‘Captain Cook,’ we all know I’m talking about a person, and that it’s probably the same person as ‘James Cook.’ The name may immediately evoke dates, concepts around voyages and sailing, exploration or exploitation, locations in both England and Australia …but a computer knows none of that context and by default can only search for the string of characters you’ve given it. It also doesn’t have any idea that ‘Captain Cook’ and ‘James Cook’ might be the same person because the words, when treated as a string of characters, are completely different. But by providing a link …that unambiguously identifies ‘James Cook,’ a computer can ‘understand’ any reference to Captain Cook that also uses that link.” (Ridge 2012)
As shown in Chapter 1, linked data conventions address this problem by encouraging the development of data resources that describe real-world things, and by defining Web standards and protocols that distinguish information objects from real-world objects. Once the solution is implemented, Web documents about Captain Cook will have a resolvable reference to the English explorer instead of the string ‘Captain Cook.’ Such a reference produces hyperlinks that confer a machine-understandable persistence to real-world objects that transcend a particular text and mimic the human reader’s ability to move from text to text, accumulating knowledge about Captain Cook or any other person, place, or thing of interest.
This chapter describes the models for the library authority files most frequently referenced in the linked data markup accessible from WorldCat.org: the Library of Congress Subject Headings, FAST, the Dewey Decimal Classification, and VIAF. In a book that surveys OCLC’s contributions to linked data models of library resource description, it is important to highlight the achievements of OCLC researchers who have developed representations for two international standards, as well as the most frequently referenced RDF dataset produced to date by the library community. This outcome depended on groundbreaking work published by the Library of Congress in 2008, as well as the contribution of many other researchers who recognized the primacy of references to real-world objects in bibliographic descriptions and realized that library authority files were designed to achieve the same goal.
Chapter 1 pointed out that authority files were the first data resources maintained by the library community to be modeled as linked data, perhaps because they imply a solution to the ‘Things, not Strings’ problem. For example, consider the record fragments shown in Figure 2.1. At the top is a human-readable view of a MARC 21 bibliographic record that describes the book The Journals of Captain James Cook on his Voyages of Discovery, which was written by a person named James Cook who was born in 1728 and died in 1779. The ‘Author’ field identifies the author with a formatted string; the same string is repeated as a subject in the ‘Subject’ field because one of the subjects of James Cook’s journal is James Cook himself. This string also appears in the ‘Name’ field of the record below it, which is based on the MARC Name Authority record for James Cook. The authority record associates this string with a database record identifier, ‘78091496,’ and informs the human reader that the string ‘Captain (James) Cook’ is a variant form. The bibliographic record shown in Figure 2.1 is said to be ‘authority-controlled’ because a definitive link has been established between the author or subject in a description of a creative work and a unique record in the MARC Name Authority file. Authority control makes it possible to assemble a collection of resources managed by libraries that are by or about the person named James Cook who lived between 1728 and 1779, excluding authors with the same name who lived in the 19th and 20th centuries and wrote books about law, oil and gas geology, and organic chemistry.

In other words, an authority-controlled MARC record solves part of the problem identified by Mia Ridge. A machine process acting on such records can detect that ‘James Cook’ and ‘Captain Cook’ are alternative forms of the same name, and can thus build a context of information extracted from a set of records containing the same disambiguated strings. In the linked data idiom, this outcome is possible because a person has been identified and linked to an authoritative resource, which contains links to other real-world objects.
However, a legacy library authority file does not automatically qualify as a dataset that conforms to the principles of linked data. The key piece of information is not a URI, but a privileged string, or an authorized heading, which serves as an index into a database of authority file records. The heading must be copied verbatim into every record or Web document describing a resource that is by or about Captain James Cook. The link is severed if the heading is misspelled or translated into another language or if it is revised by the authority file editors. Moreover, the link is not globally unique because many national libraries in addition to the Library of Congress maintain authority files that refer to Captain Cook and may define different authorized headings.
In a narrow sense, the conversion of a library authority file to a linked dataset is a technical upgrade that converts records to a graph or network of RDF statements, defines globally unique URIs, and assigns these URIs to the task that is now performed by authorized headings. More broadly, however, the adoption of linked data conventions exerts pressure to change the semantics of the library authority file. As a resource for the library community, the authority file contains information about the strings used to identify titles, authors, and subjects in the published record. To become more broadly useful, however, library authority files must evolve into authoritative hubs about the people, places, and concepts that populate the resources managed by libraries and appear prominently in the broader web of data. The essential insight driving this transformation is that references to the things in a resource description are more valuable, versatile, and reliable than the string values that only human readers can interpret.
2.2 From Authority Records to RDF Triples
This section describes the evolution from a legacy library standard to the first drafts of library authority files modeled as linked data. It is an intellectual history of sorts, which starts with an the examination of the similarities and differences between strings represented in library authority files such as ‘Voyages around the world’ and ‘Captain James Cook.’ From there, the exposition builds up the corresponding linked data models and shows how they are implemented in several of the oldest, largest and most widely used RDF datastores in the library community.
Both strings appear in the hypothetical bibliographic description shown in Figure 2.1, where it is easily inferred that the first is the subject of the book The Journals of Captain James Cook on his Voyages of Discovery, and the second is the author. Authoritative sources for the names of subjects and authors include the Library of Congress Subject Headings (or LCSH), the Library of Congress Name Authority File, the Faceted Application of Subject Headings (or FAST), and the Dewey Decimal Classification (or the DDC). They are compatible with the Simple Knowledge Organization System, or SKOS, an RDF meta-vocabulary that was first released in 2004 and promoted to a W3C Recommendation in 2009 (Miles and Bechhofer 2009b). Because SKOS is flexible enough to model thesauri, taxonomies, folksonomies, classification schemes, terminologies, glossaries, and other controlled vocabulary lists, standards experts quickly recognized the overlap with the MARC 21 Format for Authority Data (LC 2014d), the core standard that governs the design of library authority files.
Since the MARC 21 Authority Format is the only permissible carrier for the names, subjects, and classification numbers that qualify as controlled access points in a MARC 21 bibliographic record, the linked datasets containing most of the URIs that are referenced in the RDF statements accessible from WorldCat.org are expressed in SKOS. Nevertheless, the models derived from SKOS have to be supplemented with concepts defined in other Web vocabularies, as we will show.
2.2.1 The MARC 21 Authority Format
A pair of MARC 21 authority records anchors the discussion that follows. Figure 2.2 is an excerpt from a Library of Congress Subject Headings topical authority record for the heading ‘Food preferences,’ and Figure 2.3 is a similarly abridged Library of Congress Name Authority record for the heading ‘Twain, Mark, 1835-1910.’ In both records, the strings appearing after the $a subfield codes are the literal values that are copied when human catalogers create a MARC 21 bibliographic record. Compound headings such as ‘$a Nutrition $x Psychological aspects’ or ‘$a Twain, Mark, $d 1835-1910’ can be algorithmically converted to human-readable formats, ‘Nutrition—psychological aspects’ and ‘Twain, Mark,—1835–1910.’ Figures 2.2 and 2.3 represent abridged versions of the full records; the complete versions can be accessed from id.loc.gov by entering the codes listed in the 001 fields as queries and viewing the results as MARC-XML.

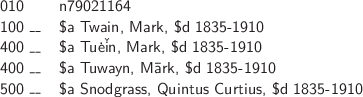
The thesaurus structure of the authority record for the topical heading, shown in Figure 2.2, is clearly evident. The 010 field is the Library of Congress Control Number, or LCCN, and can be understood as a unique identifier for the term because a carefully edited authority file maintains a one-to-one relationship between a term and a record. The 150 field contains the authorized form of the term that is licensed to appear in a controlled access field such as 650 in a valid MARC 21 bibliographic record. The 450 field contains an unauthorized equivalent and the 550 fields list related terms, i.e., other authorized headings whose meaning is associated with the one listed in the 150 field. Though ‘related’ is a slippery term, the presence of the code ‘g’ in the $w subfield identifies the headings ‘Food habits’ and ‘Nutrition’ as having broader meanings than ‘Food preferences.’ Still, no precise relationship can be inferred for the compound heading ‘Nutrition—psychological aspects.’
The name authority record shown in Figure 2.3 has essentially the same structure as the topical record, except that the field numbers are multiples of 100 instead of 50, marking this record as a description of a personal name instead of a topic. But the thesaurus structure is overlaid with features that apply only to personal names and the entities behind them. As in the topical record, the LCCN is available from the 010 field, and the preferred term ‘Twain, Mark,—1835–1910’ is listed in the corresponding 1xx field. But the $d subfield lists ‘dates associated with the name’ (LC 2014d) that are usually interpreted as the person’s birth and death dates. Similarly, the 400 fields represent alternative, or unauthorized, forms of the preferred heading. But the alternative headings for personal names are restricted to those rendered in different character sets and transcriptions, such as ‘Tuė
 n, Mark $d 1835-1910,’ reflecting the fact that the works of this well-known literary figure have been translated into many languages. Finally, the 500 field, like the corresponding 550 field in the MARC authority record for topical headings, identifies cross-references to other authorized headings related to ‘Twain, Mark $d 1835–1910.’ Among them are ‘Snodgrass, Quintus Curtius $d 1835-1910,’ shown in Figure 2.3; as well as ‘Conte, Louis de$d 1835-1910,’ and ‘Clemens, Samuel Longhorne $d 1835-1910,’ shown in the complete record available from http://id.loc.gov/authorities/names/n79021164. But most of these headings also have a specialized interpretation applicable only to personal names. Mark Twain, Quintus Curtius Snodgrass, and Louis de Conte are the names of literary personas coined by the true author, Samuel Longhorne Clemens. Some of this subtlety is acknowledged in the 663 field (‘Complex See Also Reference-Name’), which contains a note to search for works of this author written under other names.
n, Mark $d 1835-1910,’ reflecting the fact that the works of this well-known literary figure have been translated into many languages. Finally, the 500 field, like the corresponding 550 field in the MARC authority record for topical headings, identifies cross-references to other authorized headings related to ‘Twain, Mark $d 1835–1910.’ Among them are ‘Snodgrass, Quintus Curtius $d 1835-1910,’ shown in Figure 2.3; as well as ‘Conte, Louis de$d 1835-1910,’ and ‘Clemens, Samuel Longhorne $d 1835-1910,’ shown in the complete record available from http://id.loc.gov/authorities/names/n79021164. But most of these headings also have a specialized interpretation applicable only to personal names. Mark Twain, Quintus Curtius Snodgrass, and Louis de Conte are the names of literary personas coined by the true author, Samuel Longhorne Clemens. Some of this subtlety is acknowledged in the 663 field (‘Complex See Also Reference-Name’), which contains a note to search for works of this author written under other names.
2.2.2 MARC 21 Authority Records Modeled in SKOS
In 2008, a team led by Ed Summers converted the Library of Congress authority files into SKOS RDF/XML (Summers et al. 2008). In May 2009, the Library of Congress made the LCSH vocabulary modeled as SKOS publicly available at http://id.loc.gov, and in 2010 published the LC Thesaurus of Graphic Materials (Ford 2010).
A SKOS description derived from the Summers project that corresponds to the MARC 21 Authority record in Figure 2.2 is shown in Figure 2.4. The contents are modeled as a skos:Concept, defined in the specification as “an idea or notion; a unit of thought” (Miles and Bechhofer 2009c). The URIs are designed to guarantee uniqueness and persistence by systematically zeroing in on the concept—first identifying the publisher (‘loc.gov’), then the class (‘authorities’) and subclass (‘subjects’) of the curated resource to which the data belongs, and terminating with the LCCN for an individual record (Miles and Bechhofer 2009b).

Since the conversion was done by the Summers team using lexical mappings, the SKOS description presents the same essential content available in the original MARC 21 record. For example, the 150 field is represented as skos:prefLabel and the 450 field is translated to skos:altLabel. The slightly more complex semantics of the 550 field requires a map to skos:related unless a $w field containing the code ‘g’ is present; in which case, skos:broader is more accurate. As we noted above, 550 fields are authorized Library of Congress terms and would thus have their own URIs in the SKOS representation. Accordingly, the three SKOS ‘Concept’ classes whose skos:prefLabel values are ‘Food habits, Nutrition,’ ‘Nutrition—Psychological aspects,’ and ‘Taste’ can be accessed from the URIs listed at the bottom of the figure. But since ‘Food selection’ is an unauthorized heading and does not have a corresponding authority record, no URI can be assigned. As a result, it appears as a string even in the richer SKOS representation.
Figure 2.5 contains the SKOS description corresponding to the MARC 21 Name Authority record for ‘Twain, Mark,—1835–1910’ shown in Figure 2.3. It is structurally identical to the SKOS description for ‘Food preferences.’ It is typed as a skos:Concept; the URI is built using the same pattern, except that the data subclass is ‘names,’ not ‘subjects’; and the analogous MARC 100 and 400 fields map to skos:prefLabel and skos:altLabel, with the same consequences for navigation. As in the topical description, the authorized headings that appear in the MARC 500 field have their own authority records from which URIs can be constructed. Thus the URIs listed as objects of the rdfs:seeAlso property resolve to descriptions whose respective skos:prefLabel data values are ‘Clemens, Samuel Langhorne, 1835-1910,’ ‘Snodgrass, Quintus Curtius, 1835-1910,’ and ‘Conte, Louis de, 1835-1910,’ another pseudonym.

Mapped to SKOS, the two MARC 21 authority records have the same labels, but the semantics are inescapably different, and the SKOS model is a better fit for the description of topical headings. Since the Library of Congress Subject Headings have a thesaurus-like structure, a controlled string such as ‘Food preferences’ is not explicitly defined, but it is assumed to be the name of a concept that can be positioned in a larger ontology. In the abridged MARC 21 authority record shown in Figure 2.2, this position is suggested informally through the list of broader and related terms, but the MARC 21 standard also permits a more precise statement with the 053 field, whose value is a code defined in the Library of Congress Classification. As we have seen, these relationships can be expressed naturally and with relatively little loss of information through skos:Concept, skos:prefLabel, skos:altLabel, skos:broader, and skos:related.
The larger context required for interpreting the string ‘Twain, Mark,—1835–1910’ is not a thesaurus or ontology, however, but a slice of history in which a person named Samuel Longhorne Clemens was born in 1835, published works of literature using the pseudonyms ‘Mark Twain,’ ‘Quintus Curtius Snodgrass,’ and ‘Louis de Conte,’ and died in 1910. To ensure consistency with other authority records, the MARC 21 name authority record declares an authorized form, which is derived from the name of the author listed on the title pages of Mark Twain’s published works. As we have seen, the authority record for Mark Twain also contains unauthorized forms of his name, coded with the skos:altLabel property, which are coined by the translators of his novels and essays. But the names listed in the 500 field of the MARC Authority record are coded with rdfs:seeAlso, a property that makes the stronger assertion of referential equivalence: in other words, Mark Twain, Samuel Longhorne Clemens, Qintus Curtius Snodgrass, and Louis de Conte are exactly the same person.
This information can be coded as a SKOS description, but the result is semantically odd. First, the underlying structure is not a set of thesaurus relationships, but a real-world identity with several names, none of which are explicitly labeled as a given name, a pseudonym, or a translated or transcribed name. Second, the controlled string is not literally the attested name of the author, but is instead a complex statement containing the name plus the author’s birth and death dates, which are perhaps more reasonably modeled as properties that are crucial for establishing a reference to a person who once lived. Finally, the string ‘Twain, Mark,—1835–1910’ is modeled as a ‘Concept,’ not a ‘Person’ entity. As a result, a description using the SKOS URI defined in Figure 2.5 would state that the well-known author of Huckleberry Finn is a skos:Concept whose preferred label is ‘Twain, Mark,—1835–1910,’ not a person who was born in 1835 and died in 1910 and wrote under the name ‘Mark Twain.’ Clearly, personal names are richer than a model derived from a that is mapped to SKOS, a shortcoming that requires much of the rest of this chapter to address.
2.2.3 The FOAF Model of ‘Person’
The ‘Friend of a Friend’ (or FOAF) specification was developed in early 2000 as a broad, easy-to-use vocabulary that could be used to describe things on the Web. In the next decade, FOAF evolved into a de facto RDF standard for describing people and social groups; and more broadly, the “basic information about people in present day, historical, cultural heritage and digital library contexts” (Brickley and Miller 2014). From its inception, FOAF was designed to be interoperable with other vocabularies, tools, and services developed for the Semantic Web.
Both FOAF and SKOS can both be used to model important facts about strings such as ‘Mark Twain,’ but they produce fundamentally different results. The SKOS description shown in Figure 2.5 models Mark Twain as a ‘Concept’ entity that can be referred to using a variety of strings managed as authorized headings by library catalogers. But the corresponding FOAF description shown in Figure 2.6 models Mark Twain as a ‘Person’ entity and defines a list of identifying properties such as foaf:name, foaf:birthday, and foaf:gender. As a result of this distinction, the URIs for the two descriptions resolve to different kinds of resources, or real-world things.

In addition, the identifying information in the FOAF description goes well beyond what can be expressed in the MARC 21 Authority standard and the semantics of the thesaurus that underlies the SKOS specification. Thus the various strings that have been collected in the FOAF description are explicitly identified as names; and the name given at birth, ‘Samuel Longhorne Clemens,’ is distinguished from pseudonyms and other assigned names. The name strings have also been decoupled from the semantics of the thesaurus underlying the SKOS models, which enforces distinctions among the preferred label ‘Twain, Mark, 1835-1910’; the alternative label ‘Tuė n, Mark, 1835-1910’; or a related ‘Concept’ entity with the preferred label ‘Snodgrass, Quinton Curtius, 1835-1910.’ Instead, the FOAF description can be enhanced with nicknames, acquaintances, homepages for work and school, thumbnail images, and lists of publications—many of which are, of course, more appropriately applied to living Internet-aware people than to historical figures.
n, Mark, 1835-1910’; or a related ‘Concept’ entity with the preferred label ‘Snodgrass, Quinton Curtius, 1835-1910.’ Instead, the FOAF description can be enhanced with nicknames, acquaintances, homepages for work and school, thumbnail images, and lists of publications—many of which are, of course, more appropriately applied to living Internet-aware people than to historical figures.
The foaf:focus property shown in Figure 2.7 can be used to associate a resource modeled as skos:Concept to a description of a tangible thing such as foaf:Person. This property was designed to interoperate with descriptions encoded in the SKOS vocabulary “to help indicate specific things (typically people, places, artifacts) that are mentioned in different SKOS schemes (e.g., Thesauri)” (Brickley and Miller 2014). It should be noted that the idea behind the foaf:focus property is not unique to the FOAF vocabulary. The MADS vocabulary has a similar property for associating a description with a real-world object, madsrdf:identifiesRWO, which is modeled as a sub-property of foaf:focus (LC 2012), though this solution is less commonly used.

The foaf:focus property is now an established convention for associating skos:Concept descriptions with other entities. It is used in the VIAF model of ‘Person’ described later in this chapter.
2.2.4 The Library of Congress Authority Files
The 2008 publication of the Library of Congress authority files as a collection of 2.6 million RDF triples was the first demonstration of its kind in the library community, a proof of concept of the affinity between library authority files and linked data. The initial project produced a SKOS model that described personal, geographic, and corporate names as well as topical concepts (Summers et al. 2008). This work also demonstrated how controlled vocabularies could be systematically converted into RDF, and realistically stored, disseminated, maintained, and accessed. The result was a procedure that is completely automated and explicit enough to commit to a production schedule. This workflow has been so widely replicated that library data architects now routinely speak of ‘SKOSifying,’ or converting library authority files to SKOS, as we did at OCLC with the initial RDF version of FAST and the top schedules of the Dewey Decimal Classification.
In the first step, the resource URIs are designed. As we noted above, the URI for a concept managed in a Library of Congress authority file mentions the Library of Congress Control Number, or LCCN, a unique record identifier. An earlier experiment by Harper (2006) had relied on the preferred string label to achieve the same goal, but this design was ultimately replaced with the LCCN because it is more persistent.
The URIs published by the Summers team also implement a recommendation stated in the Cool URIs documentation (Sauermann and Cyganiac 2007) for referring to non-document resources such as ‘Concept’ and ‘Person’ entities. The CoolURIs document defines two URI patterns, containing either a ‘hash’ or a ‘slash,’ which are interpreted using different HTTP protocols. HTTP servers respond to a ‘hash’ pattern such as http://example.com/about#alice by truncating the URI to a document about Alice, which is delivered in a format requested by the user through content negotiation via HTTP 200, the usual protocol for delivering documents on the Web. By contrast, browsers respond to a URI with a ‘slash’ preceding the word ‘alice,’ such as http://www.example.com/alice, by redirecting the request to a document about Alice using the HTTP 303 protocol, which signals a reference to a non-deliverable resource and substitutes an authoritative document about it instead. Though the semantics of the second solution are arguably clearer, the Summers team implemented the first solution and appended ‘#concept’ to the end of each LCSH URI, observing that it is more efficient to compute because it does not require a redirection step. The Summers team also defined an ‘about’ document for each resource instead of using the hash URI to deliver an individual section of a document that describes multiple resources. As a result, their ‘hash’ solution maintains a one-to-one relationship between documents and the non-document resources they describe, just as the ‘slash’ solution does, making the differences between the implementations relatively slight.
In subsequent steps, SKOS statements are generated from the legacy source. Though most of the SKOS statements can be produced through lexical relabeling, some need to be assembled through a more complex algorithmic process. For example, many use cases for library authority data require that the language of cataloging be identified, which is available from the 040 field in the MARC 21 Authority Format.
Compound or pre-coordinated headings also require special handling. For example, the heading ‘$a Nutrition $x Psychological aspects’ is converted to the string literal ‘Nutrition—psychological aspects’ in SKOS RDF and associated with a URI that refers to the psychological aspects of nutrition. This result is possible only if the compound heading has a corresponding LCSH record; otherwise, compound headings would have to resolve to the multiple URIs of their component terms. Since pre-coordinated subject heading schemes use complex, highly productive rules to create phrases that uniquely describe a resource or anticipate a user’s search term, the set of attested headings will always be larger than the set of records that define them in the subject heading scheme. We will revisit this issue in the concluding chapter of this book because we view it as an inherent limitation of the linked data paradigm. Nevertheless, post-coordinated subject heading schemes, which contain only individual words or atomic concepts that users combine when searching, may be more a natural fit for the requirements of the linked data architecture.
Though these issues can be addressed through analysis and semi-automated processing, the Summers team also assembled a realistic technology stack that solved the problem at scale. Acknowledging their predecessor (Harper 2006), they demonstrated that large datasets could be produced for persistent, production-quality systems using publicly accessible and lightweight tools. Despite some issues with the backward traversal of XML nodes required to produce full URIs instead of string literals for broader and narrower terms, the conversion processes could be built with XSL stylesheets or Python scripts. On the front end of the system, additional stylesheets implemented content negotiation protocols that produced MARC-XML and multiple RDF syntaxes.
2.2.5 The Faceted Application of Subject Terminology
The procedures and conventions defined in the Summers project were easily replicated when OCLC developed the RDF model for the collection of vocabularies commonly known as FAST, or the ‘Faceted Application of Subject Terminology.’ Initiated in 1998, FAST was developed jointly by OCLC and the Library of Congress to provide a post-coordinated version of the Library of Congress Subject Headings (Chan and O’Neill 2010). The redesign has the welcome effect of simplifying the rules for building compound headings, which translates into a low-overhead solution for assigning patron-friendly subject terms to Web resources, archives, journal articles, and other materials that do not usually undergo traditional authority control (Mixter and Childress 2013). As a post-coordinated vocabulary, FAST can also be more easily translated into RDF because authority records already exist for all of its approximately 1.7 million headings.
The FAST vocabulary was originally released as an RDF dataset in December 2011 (OCLC 2011b) and was significantly revised in 2013. The new version incorporates several high-level classes defined in Schema.org, such as ‘Topic,’ ‘Person,’ ‘Organization,’ ‘Place,’ and ‘Event,’ which permit the formulation of ordinary-language descriptions that still retain the structure and provenance expected of a controlled vocabulary maintained by the library community.
Figure 2.8 shows a description of the FAST concept ‘Food preferences.’ Because of its LCSH source, this description consists primarily of the familiar set of preferred and alternative headings and related concepts, modeled using SKOS classes and properties. The schema:sameAs property establishes an equivalence with the corresponding LCSH description. The FAST URI is globally unique, like the LCSH antecedent, because it contains the legacy database record identifier ‘930981’ as a token. But in a deviation from the LCSH design, FAST URIs implement the ‘slash’ solution described above because they refer to concepts and other non-document resources, which are described in the Generic Document retrieved by the HTTP 303 redirect protocol. The Generic Document itself is simply the set of statements such as those shown in the figure, which can also be delivered through content negotiation as MARC 21, HTML, or RDF/XML. The ‘slash’ solution was adopted for FAST and OCLC’s other linked data models because it can be easily managed by standard RDF utilities.
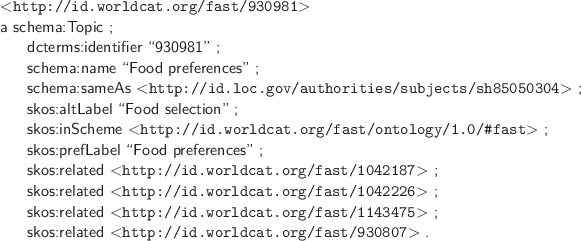
The FAST RDF is available as a bulk data dump (FAST 2014a), and individual headings can be accessed from a search interface at (FAST 2014b). The URIs for FAST headings are also automatically assigned to bibliographic descriptions accessible from WorldCat.org.
2.2.6 The Dewey Decimal Classification
The top-level summaries in 11 languages of the Dewey Decimal Classification, or the DDC, were first published as RDF in 2009. Subsequent enhancements to the RDF dataset were published at http://dewey.info, which established persistent URIs for classes and index terms. In 2012, the DDC RDF was upgraded to include all concepts defined in the full edition, DDC 23. The evolution of the mature model is described in Panzer (2008), Panzer and Zeng (2009), and Mitchell and Panzer (2013). We point out some of the highlights of their analysis here.
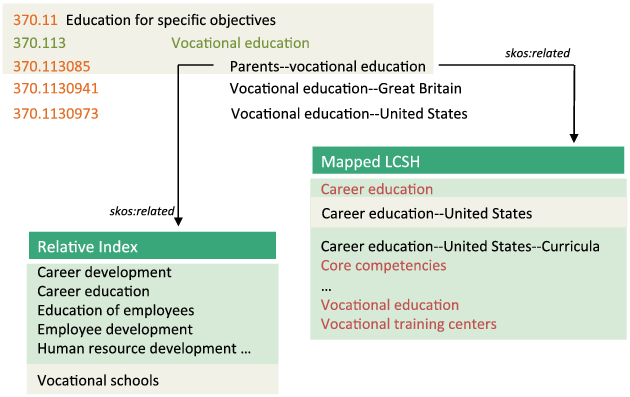
Key details of the model are illustrated in Figure 2.10, an image adapted from Panzer (2008). This example shows a fragment of the concept space for the Dewey class corresponding to the number ‘370.113,’ whose preferred English label is ‘Vocational education.’ The terms displayed against a grey background are reproduced in Figure 2.10 as a set of slightly simplified RDF/Turtle SKOS statements. As in other knowledge organization schemes with a thesaurus-like structure, the DDC concept labeled ‘Vocational education’ appears in a hierarchy, which contains the class number ‘370.11,’ or ‘Education for specific objectives,’ as a broader concept and ‘370.113085,’ or ‘Parents—vocational education,’ as a narrower concept. In addition, ‘Vocational education’ is associated with concepts defined in other Dewey class hierarchies through entries in the Dewey Relative Index, such as ‘Vocational schools,’ the English-language preferred label for the class number ‘373.24.’ LCSH concepts such as ‘Career education—United States’ are also mapped to the Dewey class ‘370.11’ through a separate editorial process. These relationships are modeled using the properties skos:prefLabel, skos:broader, skos:narrower, and skos:related. In addition, the DDC model for ‘Vocational education’ includes the property skos:notation , which identifies the language-independent class number ‘370.11.’
Figure 2.10 also shows that Dewey classes are modeled using skos:Concept with a variation of the resolution semantics described in Summers et al. (2008). The URI is built from six kinds of tokens: the name of the project, ‘dewey.info’; the name of an object defined in the Dewey metalanguage, such as ‘class,’ as in this example—or ‘schedule,’ ‘index,’ ‘table,’ or ‘summary’; the name of the corresponding published DDC edition, ‘e23’; a date stamp for the extracted data, ‘2012-10-24’; the word ‘about,’ labeling this set of statements as a description of a non-document resource; and a language token, ‘en,’ which identifies this set of statements as an English-language description of the concept.
The URI structure implies that the terms defined in the DDC metalanguage overlap only partially with SKOS, raising many problems for the definition of an RDF model. One problem is that SKOS cannot express the meaning of the DDC ‘centered entry,’ as Panzer and Zeng (2009) argue. For example, the notation ‘T2–485’ represents ‘Sweden’ and can be modeled as a skos:Concept, while the centered entry ‘T2 - 486 - T2 - 488’ encompasses the geographical subdivisions of Sweden. The centered entry is subordinate to ‘Sweden’ and a parent to the concepts below it—i.e., the names of the individual provinces. But the centered entry is not formally defined and acts only as a placeholder for a span of numbers. As a result, no URI can be assigned. Panzer and Zeng considered modeling the centered entry as a skos:Collection, but this solution is problematic because skos:Collection and skos:Concept are disjoint classes. The relative index is another problem. For example, the Dewey class ‘616 Diseases’ has the index terms ‘Clinical medicine’ and ‘Internal medicine,’ but the relationship between the index terms and the class definition is unspecified. In the solution proposed by Panzer and Zeng, each DDC class and index term is represented as a skos:Concept. ‘Clinical medicine’ is then associated with the Dewey class ‘616 Diseases’ via the property skos:hasIndexTerm, a subproperty of skos:CloseMatch. These two problems show that SKOS is an imperfect fit for a sophisticated classification scheme. As the name implies, SKOS was developed as a ‘Simple’ ontology and was not designed to for complex vocabularies or thesauri.

Because of the mismatch between the SKOS and DDC semantics, the RDF model of the DDC is not as rich as the print version, but it is superior in other respects. For example, the SKOS dataset can be queried through a SPARQL endpoint (DDC 2014). Since the publication of the RDF dataset, the Dewey team has been investigating ways to enhance the dataset and make it more useful to users. One improvement proposed by Mitchell and Panzer (2013) is a set of links from the Dewey geographical terms to GeoNames. They recommend the use of foaf:focus, a FOAF property discussed in the next section of this chapter, to connect a skos:Concept such as ‘T2–485’ to the GeoNames entity for Sweden (which is classified as a geonames:Feature). As the authors point out, the New York Times recently published their data as RDF and connected their geographical terms to GeoNames. If the same change were applied to the DDC, articles published with New York Times headings could be discoverable through Dewey classes.
The DDC model demonstrates that SKOS is not rich enough to capture all of the information in a library authority file, even when the focus is restricted to models of topical subject headings. Although SKOS lacks some important granularity, the conversion process first defined by the Summers team is both explicit and simple enough that nearly anyone with self-taught scripting skills and access to a MARC 21-compliant authority file can conduct experiments capable of producing mature results. The most important outcome of this work is that it is now technically feasible to record the subject of a book by embedding a URI instead of the literal string, thus sidestepping the problems with maintenance and data quality mentioned in the opening paragraphs of this chapter.
2.2.7 Summary: First-Generation RDF Models of Library Authority Files
The most important outcome of the projects described in this section is a set of first-draft RDF datasets generated from legacy library authority files. Because of the close fit between the MARC Authority format and the SKOS ontology, the conversion process is well-understood and mechanical, if certain requirements are met: the source dataset has a thesaurus-like structure, there is a one-to-one relationship between a concept definition and a database record, and the record has a persistent identifier that can be repurposed into a globally unique URI. But only the largest and most widely used library authority files have been converted to RDF. Still missing are vocabularies maintained by most of the world’s national libraries, as well as vocabularies developed for many scholarly disciplines and types of specialized materials.
The new format offers the promise that library authorities can be integrated more deeply with the broader Web, while raising questions about the appropriateness of the thesaurus model for referents that are physical or tangible objects in the real world. For example, the model of a person in an ’author’ relationship to a creative work is still unsettled, though this connection should be at the very center of a model of library resource description. As the discussion has shown, the conversion of a name authority record from MARC to SKOS has simply moved the problems in the original specification to the new format.
In particular, SKOS is still a model of curated strings. When the object of description is a person and the source is a MARC authority record, birth and death dates are among those strings, though they are more naturally expressed as properties defined in a ‘Person’ class. This problem is addressed in FOAF, though only partially, because the ontology does not define a death date. In addition, FOAF does not support a well-rounded description of a person with multiple identities or personas. Of course, Samuel Longhorne Clemens might be viewed as an outlier in the literary canon because he wrote under multiple pseudonyms. But an actionable model of the ‘Person’ entity should allow for the possibility of personas with multiple names to account for a child with a nickname, a blogger with an alias, an employee with an ID, or a researcher with a standard name identifier. In the next section, this issue is revisited when we discuss the model of ‘Person’ in VIAF.
2.3 The Virtual International Authority File
The Virtual International Authority File, or VIAF, merges the data maintained in the most widely used library authority files and makes the results available to a worldwide audience of data consumers. The project was motivated by the concern that multiple national libraries maintain authorized headings for the same individuals attested in the published record, such as ‘Mark Twain,’ but produce results that are either redundant or irreconcilably different. Thus VIAF was designed to reduce the cost of library authority control through collaborative effort, creating more reliable links to, from, and among library resources.
Working initially with the Deutsche Nationalbibliothek and the Library of Congress, OCLC published the first proof-of-concept prototype in 1998 and since 2011 has offered VIAF as a hosted service. Since 2003, VIAF has been managed as an international consortium. In July 2014, the VIAF Consortium had participants from 29 countries, representing 24 national libraries and 14 other agencies. At that time, the VIAF database contained 35 million personal names, over 5 million corporate names, nearly a half million geographic names, and over two million standardized or uniform titles, or names of creative works (OCLC 2014a). This collection was built from nearly 45 million authority records, from which OCLC’s aggregation process established over 30 cross-references (Hickey 2013).
VIAF was originally developed as a database of library authority files derived from the MARC Authority standard. But in 2006, OCLC researchers began to publish some of the data as RDF. The result was a dataset containing 9.5 million entities (Hickey 2009), which has continued to grow. The VIAF RDF dataset is downloaded approximately 150 times per week and is a commonly cited RDF dataset.
Since its initial release, the VIAF RDF dataset has undergone many updates and modifications that align it more closely with the standards and best practices emerging from the linked data community. Some of the changes have been technical or stylistic, but the most fundamental change is the same one that affected the other models of library authority files we have surveyed so far in this chapter. Like FAST—and to some extent, the Library of Congress authority files—the current RDF version of VIAF is now less about curated strings for the names of concepts and more about the real-world entities whose importance has been recognized by librarianship. As in the earlier examples, the evolving RDF model for VIAF is best understood by first examining its MARC-based predecessor.
2.3.1 The VIAF Database Record Structure
A user who searches for ‘Mark Twain’ in http://viaf.org views a results list containing, among other things, a link to a description of the author of The Adventures of Huckleberry Finn and Tom Sawyer, as well as links to Samuel Longhorne Clemens, Quintius Snodgrass, and descriptions of the archives, collections, and societies that are named in Twain’s honor.
Figure 2.11 shows a partial view of the VIAF description for Mark Twain the author. The first segment lists the VIAF identifier ‘50566653’—whose meaning has evolved, in a similar way to the Library of Congress Control Number discussed earlier in this chapter.

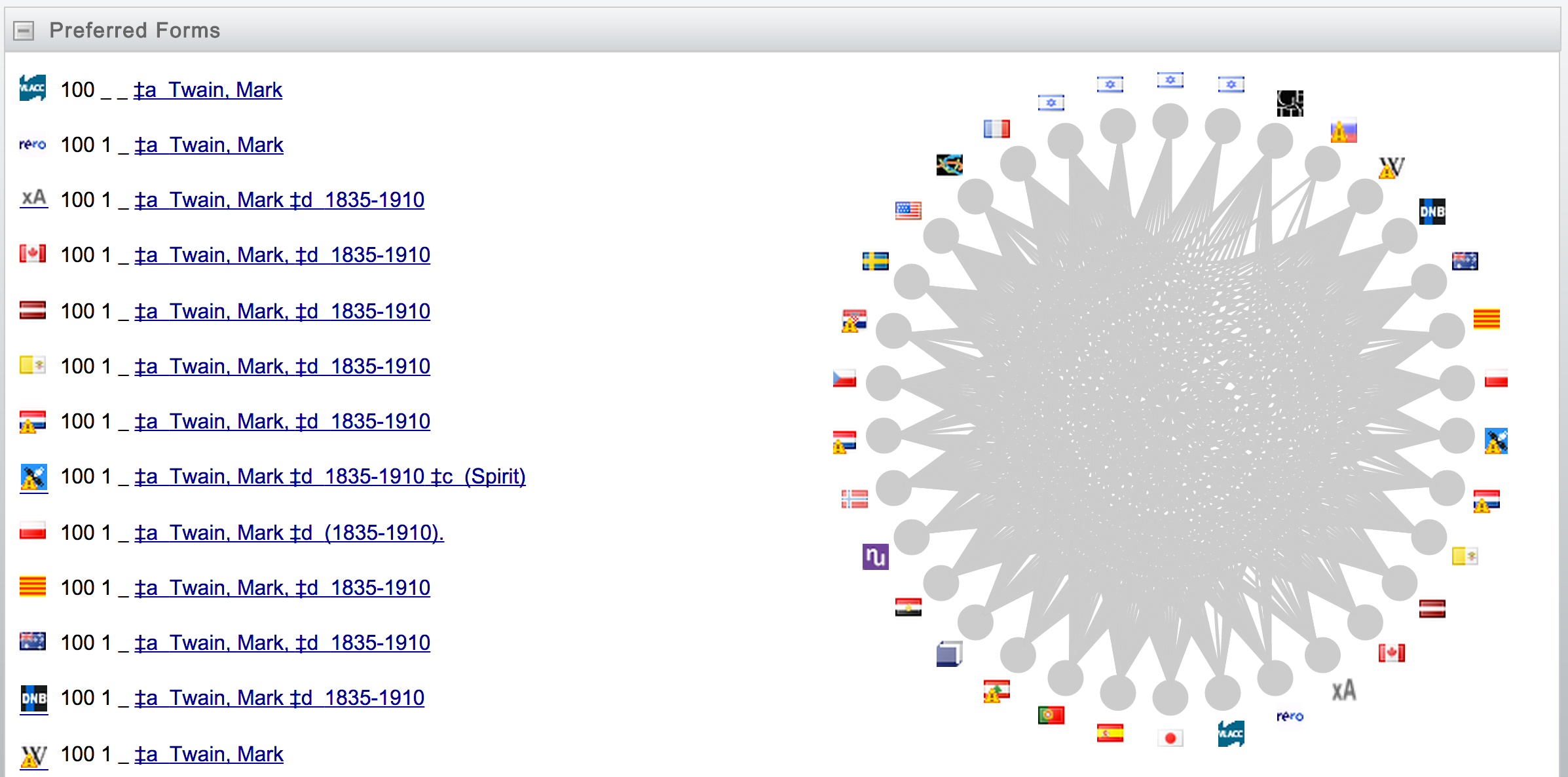
In the traditional MARC 21–oriented view visible from VIAF.org, the VIAF identifier can be interpreted as a record number for the description of Mark Twain the author. But as the key component of the URI http://viaf.org/viaf/50566653, the VIAF identifier points to the unique real-world individual, as we will explain below. The first section also lists preferred forms of Mark Twain’s name that have been extracted from authority files, whose diverse origins are represented visually by a set of icons. The complete list of preferred forms is shown in the second segment and the interconnections that have been computed by the VIAF clustering algorithms are depicted in the starburst pattern on the right. Starbursts representing internationally important historical figures such as Mark Twain are especially dense because their works are widely translated and held in libraries all over the world. Other segments not shown in Figure 2.11 link to VIAF entries for alternate and related forms of the name; uniform titles, about which we will have more to say later in this section and in Chapters 3 and 4; alternate views of the record, which we discuss below; as well as countries of publication, related names, co-authors, publishers, and publication statistics.
The last segment preserves the revision history of the VIAF identifier. Since the contents of the record are assembled from inputs provided by third parties, the identity may not be stable if it is computed from sparse or noisy data. The clustering algorithms are tuned to make conservative decisions and may produce multiple VIAF identifiers for the same individual in these circumstances, which can be merged when more data becomes available. This segment makes it possible for a human or machine process to follow the path from a deprecated identifier to the current one.
In the ‘Record Views’ section, a click on the link labeled ‘MARC 21’ reveals a record containing elements from the MARC 21 bibliographic and authority standards, as well as some locally defined fields. Such a custom design is necessary, because no existing standard adequately represents the semantics of an aggregated authority file. WorldCat cataloging data is mined to produce a ‘Derived Authority,’ which contains lists of publications by and about the person or entity of interest, co-authors, important dates and geographic locations, and other inputs to an algorithm that clusters data describing a unique identity. The ‘Derived Authority’ is combined with the controlled strings and lifespan dates obtained from the aggregated authority records to produce the ‘Processed Authority,’ which is the record accessible from the VIAF interface. This data flow is depicted schematically in Figure 2.12.
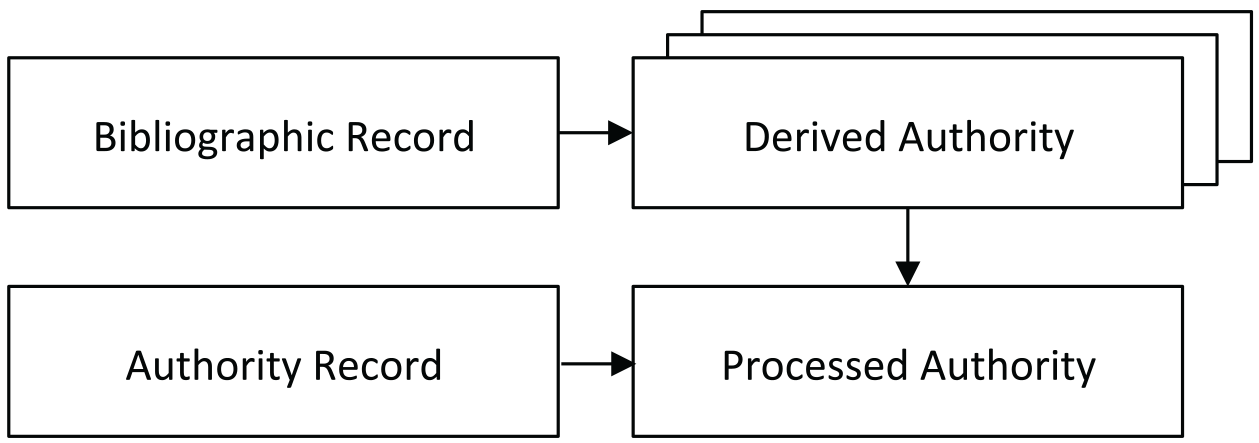
Figure 2.13 shows an excerpt of the record reconstructed from the MARC-XML view. Aside from two custom-defined fields—the 910, which contains the title of one of Mark Twain’s books, and the 370 field, which mentions the name of an important geographic location—the record resembles a MARC 21 Authority record, with one important deviation. As in the corresponding MARC 21 Authority record fragment reproduced in Figure 2.3, the 400 field represents an alternate form of the heading and the 500 field cites the preferred form of a related heading. The $2 fields contain codes that identify data contributors: the Library of Congress (LC); the Deutsche Nationalbibliothek (DNB); the Russian State Library (RSL); the National Library of Australia (NLA); and many others listed in the full version of the record.
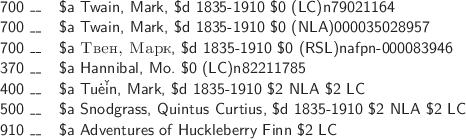
But the preferred headings are coded as 700 fields instead of 100 fields because the MARC 21 Authority standard permits multiple 700 fields but only a single 100 field per record. The semantics of the 700 field in the VIAF Derived Authority otherwise conforms to the standard. The $0 subfield lists the unique identifier assigned to the record in the source authority file for which the string listed in the $a subfield is the preferred label. In addition, the identifier is preceded by a two- or three-letter acronym for the name of the source authority, a mnemonic for the human reader or software process.
This example provides a glimpse of the large and rich VIAF database record structure, which is designed to merge library authority files developed by different national libraries into a single hub of authoritative information expressed in multiple languages and character sets. A clustering algorithm permits a software process to associate the VIAF identifier ‘50566653’ with the two other identifiers shown in Figure 2.13: ‘000035028957’ and ‘nafpn-000083946,’ the identifiers defined by the National Library of Australia and the Russian State Library. A human reader can make the stronger inference that all three identifiers refer to the same unique real-world individual, but a more sophisticated data model is required before a machine process can do the same.
2.3.2 The VIAF Model of ‘Person’
In VIAF, much of the RDF model is populated with data elements that map from the MARC 21 Authority specification to SKOS. But it is enhanced with an explicit reference to the world beyond the text. ‘Person’ was originally modeled in FOAF, but the RDF markup on VIAF was republished in September 2014 using the semantically similar class schema:Person .

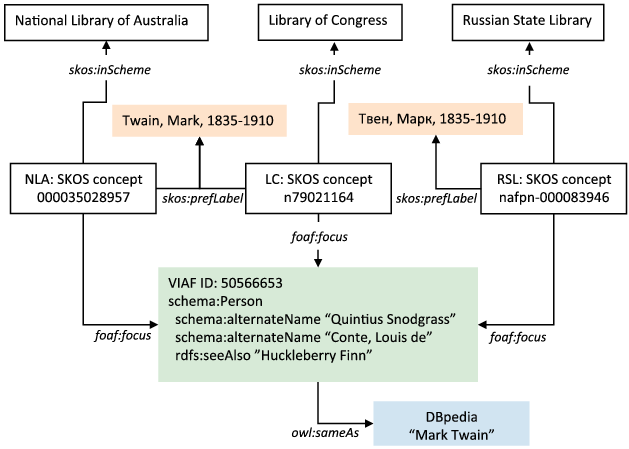
Figure 2.14 shows an RDF/Turtle version of the relevant fields of the pseudo-MARC 21 record corresponding to Figure 2.13. As in the earlier example, Figure 2.14 is a simplified excerpt designed to aid exposition. The complete description is much larger and can be viewed as RDF/XML in the ‘Record Views’ section of the relevant VIAF record. The core concept is a schema:Person with the VIAF identifier ‘50566653.’ Accordingly, the URI http://viaf.org/viaf/50566653 resolves with the HTTP 303 redirect, delivering an authoritative, content-negotiable document surrogate for the person who wrote works of literature under the name ‘Mark Twain.’
Many of the statements in the first block describe Mark Twain using properties from Schema.org, converting the controlled string imported from a library authority file source to a structured format that identifies the first and last names and lifespan dates. The owl:sameAs statement establishes a referential equivalence between the people named ‘Mark Twain’ described in VIAF and DBpedia, an RDF-encoded structured dataset extracted from Wikipedia. The statements with the schema:alternateName property contain the translated and transliterated forms of the name ‘Mark Twain.’ The rdfs:seeAlso statement establishes a referential identity between the person named 'Mark Twain' that the VIAF description is about, and the person with the same name who is described in other library authority files as the author of Huckleberry Finn.
Unfortunately, the relationships between the real-world person given the name ‘Samuel Clemens’ at birth and his adult identities are not yet adequately captured. Such gaps are addressable in BiblioGraph (BGN 2014a), an extension vocabulary for Schema.org designed to meet the needs of librarians, library systems vendors, and publishers, which is discussed in more detail in Chapter 3. The problem can be solved by defining the BiblioGraph term bgn:isPseudonymOf, which is used in a description of Mark Twain to create the machine-understandable statement ‘Mark Twain is a pseudonym of Samuel Longhorne Clemens.’ Conversely, bgn:hasPseudonym could be used to state that Samuel Longhorne Clemens has the pseudonymn ‘Mark Twain.’ These terms are definable as additional properties for the schema:Person class. These terms are definable as additional properties for the schema:Person class, have yet not been published in BiblioGraph because the model of a literary persona is still being developed.
The remaining RDF statements in Figure 2.14 encode descriptions of concepts modeled as skos:Concept extracted from the authority files that comprise the VIAF aggregation. They have the same internal structure. First, an entity represented in the authority file is associated with a URI. If the source authority file has been modeled as RDF by a recognized maintenance agency, the block contains a skos:exactMatch statement with a URI from the source. Of the three descriptions listed in Figure 2.14, only the concept derived from a Library of Congress source has a native URI. Otherwise, the process stream managed at OCLC generates a conditional RDF model containing URIs with a ‘VIAF’ token. Each locally constructed URI also contains a token representing an acronym for the source authority, such as ‘NLA’ for the National Library of Australia. Finally, each URI contains the unique number assigned to the concept in the source database record, such as the RSL identifier ‘nafpn-000083946.’ The skos:inScheme statement refers the reader or a machine process to more information about the authority file. A foaf:focus statement associates the description with Mark Twain, the real-world person referenced by the VIAF identifier ‘50566653.’ Finally, the statements containing the skos:prefLabel and skos:altLabel can be assigned the same interpretation as the corresponding statements in Figure 2.5: the preferred label represents a controlled string and the alternative label is an uncontrolled variant, according to the agency that controls the record.
These relationships are shown as a hub-and-spoke configuration in Figure 2.15. At the center is the core entity schema:Person, and on the periphery is a set of descriptions obtained from the aggregated authority files.
In Figure 2.15, the focal point is a schema:Person. But in the initial version of the VIAF RDF model, the class viaf:NameAuthorityCluster was defined as the hub instead, reflecting the earlier interpretation of VIAF as an aggregate of strings. Figure 2.16 shows the most important details of this model. The grayed-out elements describe the form and provenance of the source strings in essentially the same terms as the current version. The main difference is that the name strings associated with ‘Person’ entities were modeled in the viaf:NameAuthorityCluster class, while other identifying information was modeled in the foaf:Person class, which were associated through the foaf:focus property.
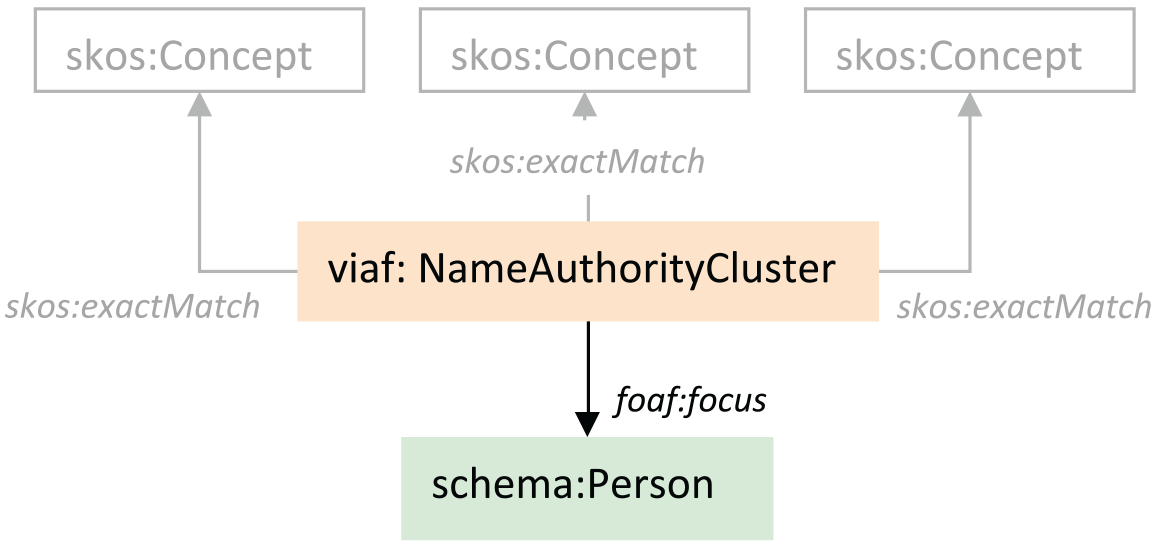
Though the links between the skos:Concept layer and the viaf:NameAuthorityCluster are arguably more straightforward in this model, the design was abandoned. One problem was that viaf:NameAuthorityCluster was an opaque artificial construct with no published definition or properties, yet it was the referent of the canonical VIAF URI, http://viaf.org/viaf/xxxxx. But it could refer only to “an accumulation of labels” (Young 2011), and not directly to a person, thus motivating the need for a separate foaf:Person class. Even so, the statements containing skos:prefLabel were available only in the source authority descriptions, not in the hub, requiring a machine process to traverse the RDF graph to locate them. Another problem was that the collection of authorized strings across multiple files made it necessary to describe relationships among the underlying concepts separately from the string labels for them, a distinction captured in the FRSAD concepts ‘Thema’ and ‘Nomen’ (Zeng, Zumer, and Salaba 2010). But a model with this detail required an additional class, skosxl:Labels (Miles and Bechhofer 2009a), an extra URI pattern that differentiated the VIAF identifier from the string label, and a retrospective conversion that was not guaranteed to be reliable.
In the end, the effort required to align VIAF with the FRSAD model was deemed impractical for everyday use. As a result of the revision of the previous model to the current one, the referent for the canonical VIAF identifier changed from an artificial construct to a real-world object. This was a radical shift that positioned VIAF to evolve into an authoritative hub of data—primarily about people, but also about a small number of places, organizations, and works—which is managed by the library community in a format that can be consumed by the broader Web. The change marked a bold departure from legacy library standards, a change that was bound to happen, because the MARC 21 Format for Authority Data was never a good fit for the semantics of a trans-national aggregation.
2.3.3 A Note about Uniform Titles
The RDF model for VIAF is the most mature and comprehensive for personal names and the people behind them. But descriptions of organizations, geographic features and locations, and creative works are also accessible by choosing the appropriate item from the menu labeled ‘Select Field’ on the VIAF search interface. Anticipating the subject of the next chapter, we note here that the description of creative works is the focus of much experimentation by OCLC researchers. Works usually make their appearance in VIAF as the so-called ‘uniform titles’ defined in MARC authority files and referenced in bibliographic records (LC 2014a).
A MARC-like representation of a description of Huckleberry Finn is shown in Figure 2.17. It is similar to the corresponding description of Mark Twain shown in Figure 2.14 because the input fields consist primarily of author-title pairs coded as MARC 700 and 400 fields. But descriptions of ‘Work’ and ‘Person’ entities are different because a Work description has a 240 ‘Uniform Title’ field and the $t subfields of the 400 and 700 fields contain string variants of a single title, not multiple titles.

An excerpt from the corresponding RDF/Turtle representation is shown in Figure 2.18. Like the description of Mark Twain shown in Figure 2.14, the top-level referent is explicitly identified as a real-world object defined in Schema.org. Here it is a schema:CreativeWork instead of a schema:Person, with properties such as schema:name, schema:alternateName, schema:author, and schema:inLanguage.

The second block of RDF statements shows one result from the Multilingual WorldCat project (Gatenby 2013), about which we have more to say in Chapter 3. It describes a Work with the VIAF identifier ‘307640027’ representing the Afrikaans translation of Huckleberry Finn, which has the bgn:translationOfWork relationship to the English-language original. The new property is defined in BiblioGraph (BGN 2014a), OCLC’s extension vocabulary for Schema.org. By mining WorldCat for evidence of translations such as this one, we can expand the scope and depth of Work descriptions in VIAF well beyond the baseline contributed by human catalogers. In the process, we demonstrate the value of a model whose core concept is no longer an aggregation of controlled strings, but a set of references to things in the world such as ‘Person’ and ‘Work’ entities.
2.4 Chapter Summary
Authority files were originally developed to make it easier for library patrons to find books by title, author, or subject. The primary use case for library authority files created a need to manage sets of specially formatted strings defined as authorized headings, embedding them in database records containing related authorized headings and unauthorized variants. When the heading is a common noun — or, more technically, a topical subject heading — such as ‘democracy’ or ‘cooking,’ the collection of formatted strings defined by the MARC Authority standard resembles a thesaurus, in which the authorized heading is the most common or stable name of a concept, while the less commonly attested unauthorized variants may have recognizable relationships to the authorized heading such as ‘Broader-than’ and ‘Narrower-than.’ As we have seen, the bridge from the record-based formats of traditional authority files to a web of machine-processable statements modeled as linked data can be easily crossed, perhaps because models for library authority files encode some of the most important prerequisites, such as persistent identifiers and implicit references to world outside collections of strings. Semantic Web models such as SKOS express nearly everything that can be declared in the old data structures when the term is a topical heading.
We have also argued that controlled strings representing the names of people require a different model that is not adequately expressed in traditional library authority standards. Establishing a link between a proper noun and a unique identity is fundamentally a problem about naming and reference, not the placement of a concept definition in a thesaurus. The problem is addressed through a richer model that defines characteristics of real-world objects and is realized through a Web protocol that delivers an authoritative document as a stand-in for the object itself. This solution makes it possible to state an obvious conclusion about proper names in library authority files: the model that underlies such resources is not wrong, but incomplete, and the solution we have described is a realistic way of extending it.
The problem can be illustrated with personal names, but the same arguments apply to corporate and geographic names. In the case of geographic names, the argument that library authority files can be extended through references to resources maintained by third parties is even stronger because the real-world referents can be even more clearly secured through a reference to geospatial coordinates and other properties that have been modeled in GeoNames. Corporate names present unique modeling challenges that have not yet been addressed by librarians or modeling experts in the linked data community. For example, a model of naming and reference for corporate entities requires time and space dimensions because companies merge, split, change their names, and move around. This is a topic for future work, but we identify some of the issues in our discussion of publisher names in MARC 21 records in Chapter 4.
Once these efforts achieve maturity, however, they raise issues about the intended scope and purpose of the redesigned authority files. As linked data, descriptions of real-world objects derived from library authority files are modeled in a format that can be broadcast to the Web, where they can be leveraged more widely to construct trusted assertions about creative works, authorship, and the vocabulary of topics and subjects. In the larger context of the Web of Data, they can be augmented with links to authoritative datasets managed by third parties, such as Geonames and Wikipedia, as we have pointed out. But library authority control remains a technical specialty of librarianship, managed by established governance structures to advance the goal of improving indexes of library catalogs, primarily for the resources types defined for MARC: books, computer files, maps, archives and other mixed materials, visual materials, music, and serials. Do the enhanced RDF datasets generated from library authority files serve the same purpose? And if not, what purpose do they serve?
One answer is that the redesigned library authority files present an opportunity to expand the evidence for the current model by increasing the connectivity between library authority files and other sources of vetted information about the authors of creative works. For example, Klein and Kyrios (2013), acting as registered Wikipedians, have devised an algorithm called VIAFbot, which has produced several hundred thousand links from VIAF to Wikipedia, primarily from English-language biographies of famous authors. In a separate process, the VIAF links are propagated to non-English versions of Wikipedia via Wikidata (Klein 2013). At the conclusion of their study, Klein and Kyrios point out the mutual benefits of this effort:
“The VIAFbot initiative has connected library authority data with hundreds of thousands of pages on one of the world’s most popular websites, increasing the visibility and availability of that data and, by extension, libraries as an institution. The positive reception to the project at Wikipedia affirms the strength of libraries in performing authority control and proves the utility of this work in the era of linked data. The project offers a blueprint for similar efforts to integrate library data with Wikipedia and, perhaps even more importantly, has built good will for the library community with Wikipedia. At a time when many libraries worry about keeping up with information in a digital world, collaborations like this one offer an exciting glimpse of what libraries can still do to help connection their users with high-quality information resources.” (Klein and Kyrios 2013)
But a more far-reaching answer is that the transformation from a collection of human-readable database records to a network of machine-processable statements presents a unique opportunity to expand the scope of the model of library resource description devoted to the definition of relationships among creative works, subjects, and the agents involved in their creation or management. For example, in addition to statements such as ‘Mark Twain is the author of Huckleberry Finn, or ‘The Omnivore’s Dilemma is about food preferences,’ academic librarians are also responding to the pressure to make unambiguous, machine-processable statements that encode such assertions as as ‘Lonnie Thompson is a professor at Ohio State University and is an expert on global warming.’ ‘Tim Berners-Lee is an author of The Semantic Web So Far.’ and ‘Edessa is the capital of Orshoene.’ These statements illustrate the need to identify relationships between authors and their areas of expertise in the larger task of describing the intellectual capital of a particular university, to apply authority control to journal articles, and to manage the names important to scholarly inquiry regardless of whether they are the subjects of published works. This landscape is rapidly evolving (Smith-Yoshimura 2013; Smith-Yoshimura et al. 2014), and governed by imperatives that are sometimes at odds with the traditional practice of library authority control (Smith-Yoshimura and Michelson 2013).
Thus it is not yet clear that the results of this effort will always be applied to existing authority files. An alternative is an authoritative hub defining ‘Person’ and other entities managed with goals and descriptive practices that only partially overlap with those of traditional library authority control . Regardless of how these changes are recorded, however, the wider Web can only be enriched by the datasets endorsed by libraries. The outcome is an argument in favor of the models developed in the linked data paradigm, and a starting point for the design of hubs for other key entities that are referenced in descriptions of library resources.