CONTENTdm Linked Data Pilot
Introduction
Digital collections in libraries represent unique materials that illuminate our understanding of the world’s cultures, histories, and innovations. Traditional models of item description have rendered these materials largely invisible on the internet, and thus, hidden from researchers. Collaborating with library partners, OCLC is working to shift this paradigm to connect people with the unique digital resources that libraries hold.

Courtesy of Cleveland Public Library

Courtesy of the Huntington Library, Art Museum, and Botanical Gardens

Courtesy of Minnesota Digital Library and Northfield Historical Society
In this project, OCLC partnered with libraries and evaluated ways to increase researchers' ability to discover, evaluate, and use the digitized cultural materials in CONTENTdm repositories, while also investigating improving library staff efficiency with a better descriptive environment. The pilot project developed a linked data model for managing cultural material descriptions, built a “full-stack” Wikibase system, quantified its limitations, created new applications to improve data entry and discovery, and optimized reconciliation services for matching headings to entities.
The five organizations that participated in the pilot project were: Cleveland Public Library; The Huntington Library, Art Museum, and Botanical Gardens; Minnesota Digital Library; Temple University Libraries; and University of Miami Libraries.
The project ended in August 2020. Transforming Metadata into Linked Data to Improve Digital Collection Discoverability, a report summarizing the project’s findings, was published in January 2021.
Overview
CONTENTdm is a service for building, preserving and showcasing a library's unique digital collections.
The large volume of unique, digital content stored in CONTENTdm offers an excellent opportunity for transition to linked data. Using linked data, the wide variety of data models and descriptive practices across CONTENTdm would be significantly easier to manage for library staff and would provide rich discovery for library end-users and web browsers. Anticipated benefits of this project would be the ability to do structured searching across all CONTENTdm repositories and searching and faceting based on authority files and library-staff-defined vocabularies.
Project objectives included:
- Increase end-users’ ability to discover, evaluate, and use unique digital content.
- improved search and faceting features made possible by an entity-driven back end system
- relevant contextual information drawn from relationships to web utilities like GeoNames and WikiData
- Improve library staff efficiency with a significantly easier to manage descriptive environment.
- library staff workflow tools for these new metadata descriptive practices—these tools are initially intended for users of CONTENTdm
- cleaned-up and enhanced descriptive metadata for the digital collections contributed by the pilot participants
- entity-based descriptions that have been reconciled to known authority services or to library-staff-defined vocabularies
- library staff workflow tools for these new metadata descriptive practices—these tools are initially intended for users of CONTENTdm
The outcomes and findings from the Metadata Refinery project completed in 2016 and the linked data Wikibase prototype (Project Passage) completed in 2018 have provided great insight into how to implement a system to facilitate the mapping, reconciliation, storage, and retrieval of structured data for unique digital materials.
As with Project Passage, this project used Wikibase as the foundational, staff application aided by OpenRefine for data clean-up and reconciliation of character strings to authoritative identifiers. The project also used IIIF APIs as a connector between structured descriptive data and the digital objects.
Three organizations—The Huntington Library, Art Museum, and Botanical Gardens; the Cleveland Public Library; and Minnesota Digital Library--joined the pilot in its initial phase. Temple University Libraries and University of Miami Libraries joined at the beginning of the project’s second phase.
Project Phases
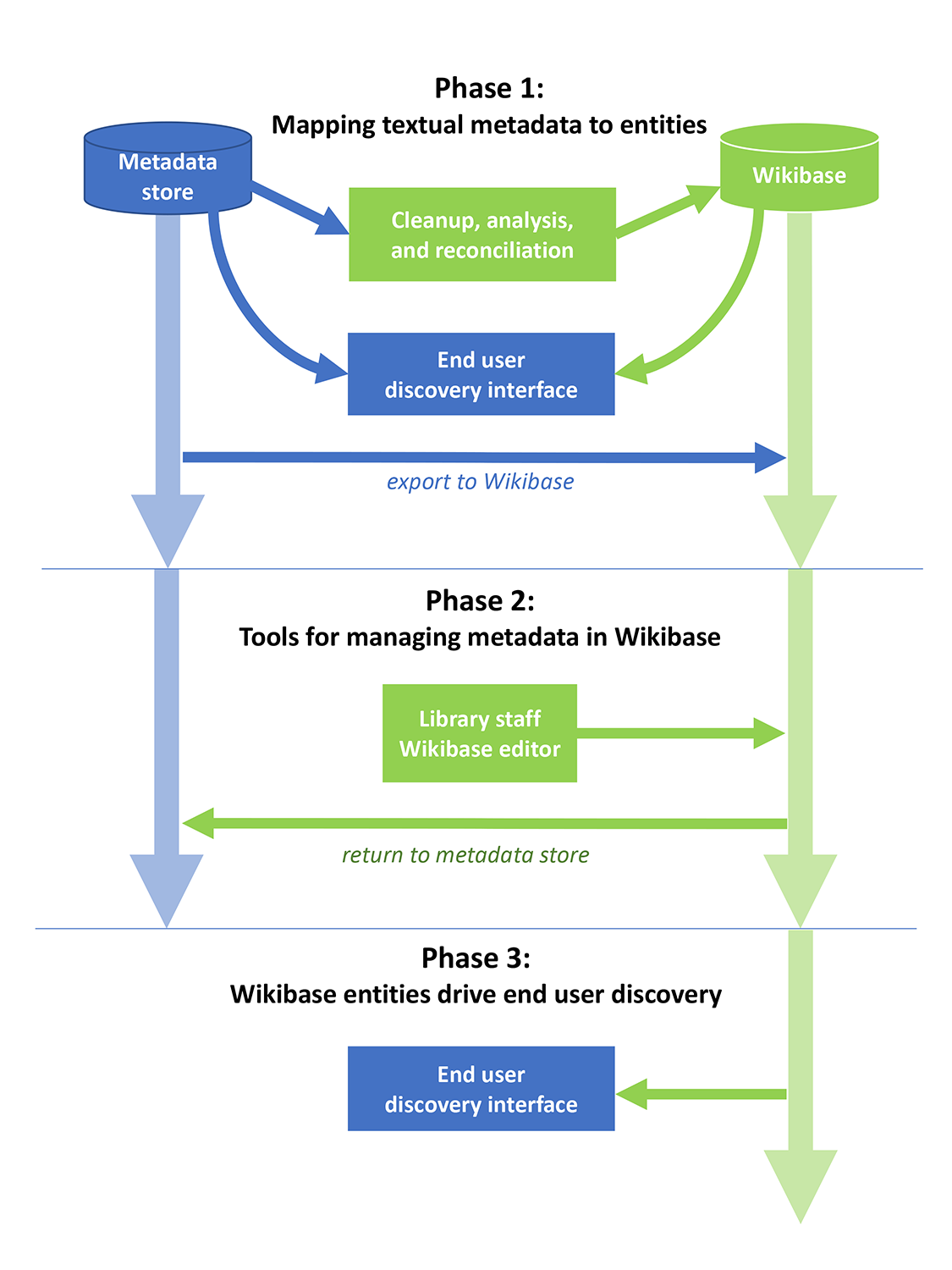
This project occurred over three phases and ran through August 2020. The first phase involved importing existing record descriptions into a local Wikibase system. The project team focused on metadata cleanup and reconciliation with authorities. The output (enriched, entity-based descriptions) informed the second phase. Phase two involved improving the search and discovery experience for digital materials and enhancing their context by bringing in the relationships with other data services. In the third phase, enrichment and reconciliation tools were refined, and the project team evaluated Wikibase as a platform on which to build CONTENTdm discovery interfaces.

Team
OCLC Membership & Research
Eric Childress
Jeff Mixter
Bruce Washburn
Global Product Management & Technology
Hanning Chen
Dave Collins
Shane Huddleston
Linked Data and IIIF Related Outputs
Publications
-

Transforming Metadata into Linked Data to Improve Digital Collection Discoverability: A CONTENTdm Pilot Project
21 January 2021
Greta Bahnemann, Michael Carroll, Paul Clough, Mario Einaudi, Chatham Ewing, Jeff Mixter, Jason Roy, Holly Tomren, Bruce Washburn, Elliot Williams
This report shares the CONTENTdm Linked Data Pilot project findings. In this pilot project, OCLC and five partner institutions investigated methods for—and the feasibility of—transforming metadata into linked data to improve the discoverability and management of digitized cultural materials.
-

Archives and Special Collections Linked Data: Navigating between Notes and Nodes
21 July 2020
OCLC Research Archives and Special Collections Linked Data Review Group
This publication shares the findings from the Archives and Special Collections Linked Data Review Group, which explored key areas of concern and opportunities for archives and special collections in transitioning to a linked data environment.
-

Utilisation des données liées dans les bibliothèques : de la désillusion à la productivité
9 July 2020
Andrew K. Pace
OCLC has been researching the use of linked data within libraries for more than a decade. It is sometimes difficult to know exactly where the value of linked data lies and what benefits we can derive from it. It is wise, therefore, to consider their usefulness from the point of view of library staff. What does "linked data productivity" mean? What would cataloging linked data change for library staff and end users? This article responds to these questions and provides some perspective on the linked data landscape for libraries.
-

Exploring Models for Shared Identity Management at a Global Scale: The Work of the PCC Task Group on Identity Management in NACO
9 December 2019
Erin Stalberg, John Riemer, Andrew MacEwan, Jennifer A. Liss, Violeta Ilik, Stephen Hearn, Jean Godby, Paul Frank, Michelle Durocher, Amber Billey
This paper discusses the efforts of the PCC Task Group on Identity Management in NACO to explore and advance identity management activities.
-

Creating Library Linked Data with Wikibase: Lessons Learned from Project Passage
5 August 2019
Jean Godby, Karen Smith-Yoshimura, Bruce Washburn, Kalan Knudson Davis, Karen Detling, Christine Fernsebner Eslao, Steven Folsom, Xiaoli Li, Marc McGee, Karen Miller, Honor Moody, Craig Thomas, Holly Tomren
“Project Passage” is an OCLC Research Wikibase prototype that explores using linked data in library cataloging workflows. The report overviews the prototype’s development, its adaptation for library use, and eight librarians’ experiences with the editing interface to create metadata for resources.