Linked Data Wikibase Prototype
OCLC Research Report

Creating Library Linked Data with Wikibase: Lessons Learned from Project Passage
In this final report out for this project, participants provide an overview of the context in which the prototype was developed, how the Wikibase platform was adapted for use by librarians, and eight use cases where pilot participants (co-authors of this report) describe their experience of creating metadata for resources in various formats and languages using the Wikibase editing interface. They also share key issues, findings, reflections, and areas for future research.
In 2017 and 2018, OCLC partnered with 16 libraries in Project Passage to demonstrate the impact of linked data for improving resource-description workflows.
• American University
• Brigham Young University
• Cleveland Public Library
• Cornell University Library
• Harvard University
• Michigan State University
• National Library of Medicine
• North Carolina State University
• Northwestern University
• Princeton University
• Smithsonian Library
• Temple University
• UC Davis Library
• University of Minnesota
• University of New Hampshire
• Yale University
The partners worked with OCLC to refine needs assessment for services. They also provided feedback by reflecting on their use of the prototype systems, responding to engagement activities, and participating in virtual meetings. This collaboration built upon past efforts, such as the Person Lookup Pilot and the Metadata Refinery effort, to demonstrate the production value of linked data services.
The pilot is now complete, but follow-up investigation continues in the CONTENTdm Linked Data pilot.
In the Passage project, the OCLC Research team worked closely with colleagues in OCLC's Global Product Management and Global Technologies to create metadata management environment built on the Wikibase platform. Project Passage took advantage of all the functionality in the Wikibase system. Shown here, from left to right, are the key components: data import, Mediawiki functions including the user interfaces, and the RDF triplestore.

The result was a fully configurable environment for experimentation, with many features for editing, crowdsourcing, native multilingual support, and full support for linked data creation. These features are mostly hidden from human users so that metadata librarians could concentrate on the work they wanted to do, not the technical details of a linked data implementation.
The red arrows identify two functions that OCLC added in response to feedback from the Project Passage partners: a “Retriever” to import data from other sources, and an “Explorer” interface that enabled pilot participants to see the impact of the relationships they added as part of their workflow.
Methodology and Timeline
Partners were given access to a live prototype system. The features and functionality are fully documented and supported by a team of product managers, analysts, engineers, and architects. The goal of the project was to inform the Global Product Management roadmap for metadata applications and services.
November 2017: Project kickoff; Discuss partnership and services with Phase 1 Partners
December 2017: Gather use cases from Phase 1 Partners
January 2018: Reconcile strings to identifiers
February 2018: Launch entity editor
March 2018: Gather enhancements and provide SPARQL endpoint; add five to ten new library partners
April 2018: Discussions with libraries resulted in a total of 16 institutions participating in the project going forward
May 2018: Launch the experimental “Explorer” UI to view entities and their relationships to other items; launch the OpenRefine API; gather feedback on the creation of creative works and prioritization of enhancements from partners
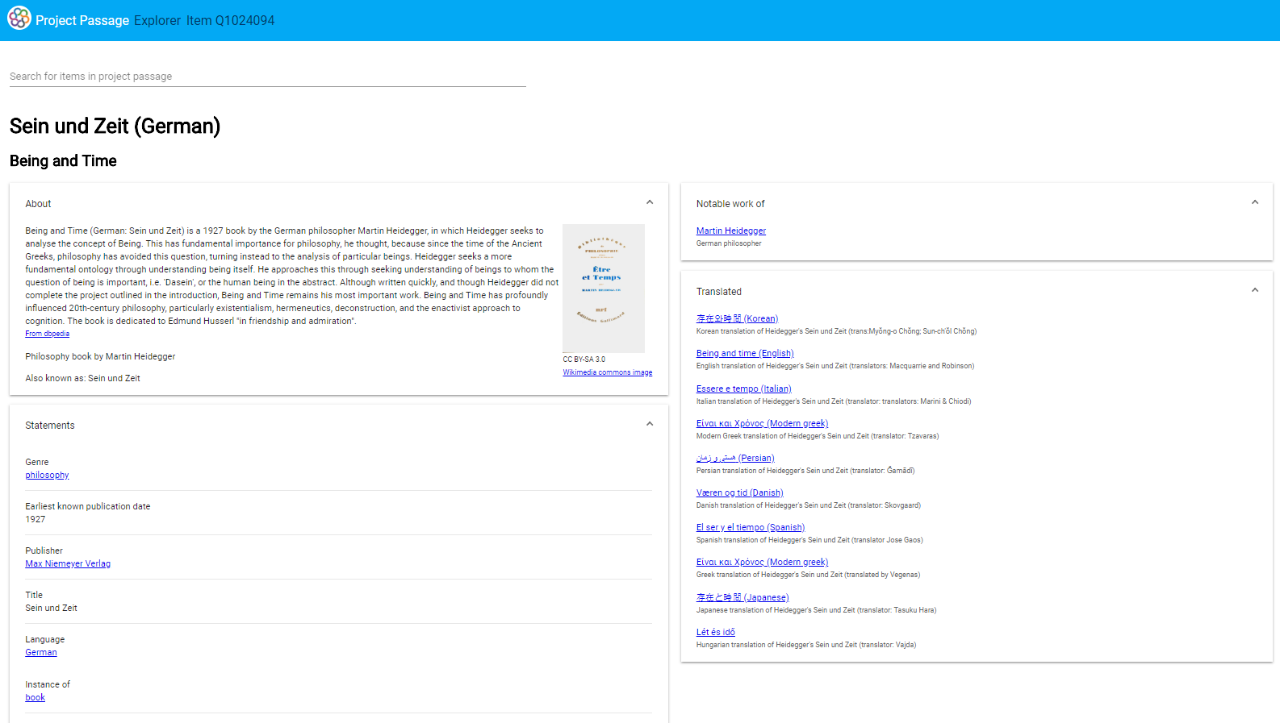
June-July 2018: Implement top enhancements suggested by library partners
- Improve indexing
- Use the Wikibase UI to search by a non-prototype identifier
- Include dates for disambiguation in autosuggest results
- Offer property-based constraints
- Provide gadget-based taxonomy navigation
August-September 2018: Explore additional top enhancements
- Provide a data import tool
- Include WorldCat data in the Explorer
- Offer an input form for descriptive data
- Batchload entities provided by partner libraries
- Document when reference sources are required for statements
Summary
The project achieved goals in three major areas.
- Collaboration: the team of OCLC staff and dozens of librarians from 16 institutions created use cases, created entities and made edits in the linked data ecosystem, used the OCLC Community Center to discuss workflows and ask questions, and participated in 28 monthly meetings and weekly “Office Hours” session.
- Reconciliation Services: experimented with cataloging workflows for entity reconciliation, using both a SPARQL endpoint and a user interfaced dubbed “The Explorer.
- Editing: managed entities in the native Wikibase user interface, the Explorer, and another experimental application, “The Retriever.”
The simple prototype described at the beginning of the project matured overt time to a robust set of third-party tools and home-grown applications to manage over a million Wikidata entities. The evolution of the project to this more comprehensive set of tools and applications was driven by project participants’ new ideas, requested features, and feedback on applications and prototype use guidelines.
A recording of the final meeting with library partners is available online:
Related Presentations

Next Generation Metadata as a Transformative Change
For many years now, OCLC has been involved in experiments, pilots, workshops, and research projects to better understand the challenges and opportunities that Next-Generation Metadata could bring to libraries. Recently, in a 2-year project with financial support from the Andrew W. Mellon Foundation, OCLC has been able to start building a shared entity management infrastructure, that will include easily accessible authoritative descriptions of works and persons, enhanced, and managed by OCLC and the library community. Building this infrastructure was yet another learning opportunity for OCLC staff and the advisory group members involved.
Conversations about Next-Generation Metadata often center around changes in resource-description workflows and, more broadly, metadata creation and knowledge work, including the opportunity for more inclusive descriptions, as well as the infrastructure required for collecting and sharing entity based data. However, it is equally important to look at “the people side of things.” Moving from records to entity description is no less than a paradigm shift that fundamentally changes the work formerly known as “cataloguing,” and with it creates new or updated skills, roles and staffing requirements, which in turn is likely to change any measurements of impact and effectiveness of descriptive work undertaken in libraries.
Libraries should be thinking strategically about the changes to staff and workflows that any implementation of Next-Generation Metadata workflows can bring, and as with any transformative change, social interoperability can help finding the partners necessary for making this effort a success.
In this session, we will share lessons learned in our work and research to date, but will also enumerate a number of remaining challenges that require library engagement to address.
Dr. Annette Dortmund for more than two decades has worked for and with European libraries of all sizes, with a focus on inventorising and analysing library needs from multiple perspectives in a changing environment characterized by broader interoperability between systems and increasing group scaling of activities. Annette joined OCLC in 2001 and has since worked in several roles across Europe. Her current focus as a Senior Product Manager lies in helping libraries navigate the challenges around the implementation of next-generation metadata workflows. Annette graduated from Mainz University with a Magister Artium in Book Sciences, Latin Philology and Comparative Literature, and was awarded a doctorate in 1998.
Topics: Linked Data, Metadata

Linked Data as a Cooperative Effort
virtual
This presentation shares how, over the last decade, OCLC has joined a number of national libraries and library organizations in publishing linked data. With the explosion of different efforts and initiatives, attention now turns to the ways in which the metadata can be maintained sustainably and in such a way to enable increased value while decreasing efforts. In January 2020, OCLC received a two-year grant from The Andrew W. Mellon Foundation to create a shared “entity management infrastructure” providing a platform to support linked data initiatives throughout the library community.
This session discusses the initiative, its progress, and what it suggests for the future of metadata work in libraries, along with what this might mean in the context of the new agreement signed between OCLC and Jisc which provides an enhanced ability to share and reuse bibliographic metadata across UK higher education institutions.
Topics: Linked Data, Metadata

Wikipedia and Libraries
virtual
Originally presented in 2020 at the Convegno Stelline (Bibliostar) 2020, this session “Wikipedia and Libraries: Partnerships to reach the future” highlights how OCLC has invested in partnerships with Wikimedia projects, and shares success stories from different types of institutions that all share a goal of connecting communities of knowledge.
The accompanying conference paper “Wikimedia and Libraries: From Vision to Practice” makes an argument that libraries and Wikimedia make great partnerships that can collaborate to strengthen shared information access goals. The paper also shares illustrative examples from OCLC’s direct experience on efforts that partner librarians and Wikimedians working in common purpose.
Topics: Wikimedia

On the Way to Library Linked Data
virtual
For more than a decade, OCLC’s Research division has been investigating the tools, standards, workflows, and strategies for making the transition from traditional bibliographic metadata to fully linked data. In this presentation, OCLC Research Software Engineers, Jeff Mixter and Bruce Washburn, will provide a perspective on the promise and potential of library linked data that is framed by OCLC Research’s past work.
In a recently completed pilot project, OCLC partnered with five institutions that manage their digital collections with OCLC’s CONTENTdm service to investigate methods for—and the feasibility of—transforming metadata into linked data to improve the discoverability and management of digitized cultural materials and their descriptions. This pilot project, reported in “Transforming Metadata into Linked Data to Improve Digital Collection Discovery”, was designed to help the OCLC team and the pilot participants better understand the following questions:
How divergent are the descriptive data practices across the institutions using CONTENTdm, and what tools are needed to make that assessment?
Can a shared and extensible data model be developed to support the differing needs and demands for a range of material types and institution types?
What is the right mix of human attention and automation to effectively reconcile metadata headings to linked data entities?
What types of tools can help extend the description of cultural materials to subject matter experts?
After metadata from different institutions and collections is transformed, are there new discovery tools that can help researchers find new—or previously hidden—connections through a centralized discovery system?
What are the institutional and individual interests in the paradigm shift of moving to linked data?
A discussion of the findings and lessons learned from investigating these questions will be the primary focus of the presentation, and we will wrap up with a look into the near future for OCLC linked data developments.
Topics: Linked Data

Wikipedia Shaming: Authority dilemmas across educational stages
Virtual
Topics: Wikimedia, Equity, Diversity, Inclusion

Bringing IIIF Manifests to life in Wikidata
virtual
Wikidata is an open knowledge base of structured data that describes any type of entity, including people, organizations, concepts, events, places, and works. Some works described in Wikidata now include a IIIF Presentation Manifest URL. In Wikidata’s default user interface, that URL appears as a link to the Manifest JSON. But Wikidata can be customized to alter the user interface and add new features. We will discuss and demonstrate a Wikidata user script that, for items that include a IIIF Presentation Manifest URL, will embed the ProjectMirador viewer and load the Manifest JSON so that the images referenced in the Manifest can be viewed in the context of other Wikidata statements about the work. The discussion will cover how the script embeds the Mirador3 viewer within a Wikidata item page and how it detects that the viewer should be added. We will also illustrate how one library is including IIIF manifests in Wikidata and about how the user script has contributed to the library's understanding of IIIF metadata and Wikidata. The demonstration will show how Wikidata user scripts are created and shared and look at ways in which Wikidata queries can uncover IIIF manifests.
Topics: IIIF, Wikimedia

Bringing IIIF Manifests to Life in Wikidata with Mirador 3 - 2021 IIIF Annual Conference
virtual
Wikidata is an open knowledge base of structured data that describes any type of entity, including people, organizations, concepts, events, places, and works. Some works described in Wikidata now include a IIIF Presentation Manifest URL. In Wikidata’s default user interface, that URL appears as a link to the Manifest JSON. But Wikidata can be customized to alter the user interface and add new features.
In this presentation we will discuss and demonstrate a Wikidata user script that, for items that include a IIIF Presentation Manifest URL, will embed the ProjectMirador viewer and load the Manifest JSON so that the images referenced in the Manifest can be viewed in the context of other Wikidata statements about the work.
The discussion will cover how the user script embeds the Mirador3 viewer within a Wikidata item page and how it detects that the viewer should be added. We will also illustrate how one library is including IIIF manifests in Wikidata, with a conversation about learnings from that work, and about how the user script has contributed to the library's understanding of IIIF metadata and Wikidata. The demonstration will show how Wikidata user scripts are created and shared and look at ways in which Wikidata queries can uncover IIIF manifests.
Topics: Wikimedia, IIIF

Creating, Curating, and Using Cultural Heritage Metadata and Resources in a Linked Data Environment
Discussion of the CONTENTdm Linked Data Pilot Project, a collaborative investigation exploring the creation, curation, and applied use of digital material linked data. This presentation will include inspiration for the work, a brief technical overview of the project, as well as a sneak peek at one of the pilot project’s most creative deliverables: the CONTENTdm Image Annotator. The presenters will demonstrate this new tool and its ability to enhance and deepen metadata description and its potential to increase the user’s understanding of digitized content. The presentation will conclude with a brief discussion of the pilot project’s impact and its potential to enhance and change CONTENTdm in the near future.
Topics: Linked Data
Team Lead
Andrew K. Pace
Executive Director, Technical Research
Project Team
John Chapman
Eric Childress
Jean Godby
Melissa Hess
Marti Heyman
Tod Matola
Jeff Mixter
Sara DeSmidt
Stephan Schindehette
Taylor Surface
Diane Vizine-Goetz
Bruce Washburn
Jeff Young