Flattening DataDir objects
How ORG.oclc.scorpion.RecordCollection.flattenDataDir() works:
 |
 |
|
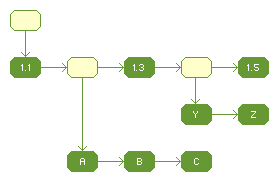
| Figure 1 DataDir object |
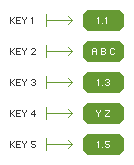
Figure 2 Hashtable object |
Figure 1 shows an example DataDir object. The blank nodes represent ASN1.CONSTRUCTED nodes, and therefore have no data. Figure 2 shows the generated Hashtable. For each toplevel node in the DataDir object, a key/value pair is created in the Hashtable, with the name associated with the node's Field ID being used as the key. If a toplevel node is ASN1.PRIMITIVE then its data becomes the value in the Hashtable. If a toplevel node is ASN1.CONSTRUCTED then the data of its children becomes the value in the Hashtable. The data for each child node are joined together with a single space character between them. For the Hashtable object in Figure 2, Key 2 is associated with ' A B C' and Key 4 is associated with ' Y Z'.
This process was used because it was a simplification and was appropriate for our data. You'll have to decide if it's appropriate for your data.
How to use ORG.oclc.scorpion.RecordCollection.flattenDataDir():
This is the method's signature: public Hashtable flattenDataDir (DataDir dir)
To use this method, you'll have to create a RecordCollection object and initialize it with a Field ID => Field Name mapping. This is done with the setFieldMap(Hashtable map) method. This method accepts a Hashtable object and returns nothing. The Hashtable should be a String to String mapping. The keys should be numerical field IDs and the values should be field names.
In addition to setting the field map, you may have to set the scoreID with the setScoreID(int id) method. This will only be necessary if you've set it in the Scorpion initialization file. If you do need to, simply pass it the integer that you specified in the file.