WorldCat Discovery API and Linked Data
This is the second post in our series introducing the WorldCat Discovery API. In our introductory remarks on the API, we told you about how the API can be used to power all aspects of resource discovery in your library. We also introduced some of the reasons why we chose entity-based bibliographic description for the API’s data serializations over more traditional API outputs. In this post we want to explore this topic even further and take a closer look at the Linked Data available in the WorldCat Discovery API.
Data Modeling
Before we look at the API output, let’s consider a traditional database-driven web application and how it might serialize some simple bibliographic data. By comparing this object-oriented data model to the Linked Data in the WorldCat Discovery API, we hope to highlight some of the areas where they differ and illuminate some of the strengths of a Linked Data, graph-based data model.
Traditional RDBMS-to-API Serialization
If you were designing a simple relational database to store and retrieve bibliographic information, you might have tables in your database for bibliographic resources, their authors/creators and maybe a lookup table so that you could add a small local controlled vocabulary for typing the things in your database. The table structure might look like the following:
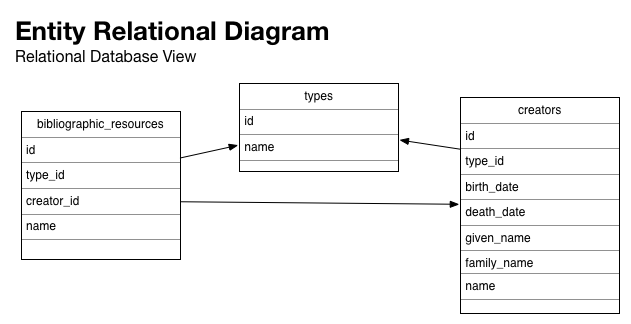
An API built upon this database might serialize a single bibliographic record from your database as:
{
"id": 820123671,
"type": {
"id": 1,
"name": "Book"
},
"creator": {
"id": 116053682,
"type": {
"id": 2,
"name": "Person"
},
"birthDate": "1957",
"deathDate": null,
"givenName": "James",
"familyName": "McBride",
"name": "McBride, James, 1957-"
},
"name": "The Good Lord Bird"
}
Entity-based Description: Linked Data Serialization
OCLC has been working hard to transform our rich collection of bibliographic data from a records-and-strings orientation into an entity-based things-and-links orientation. In this case our data example would look like the following:
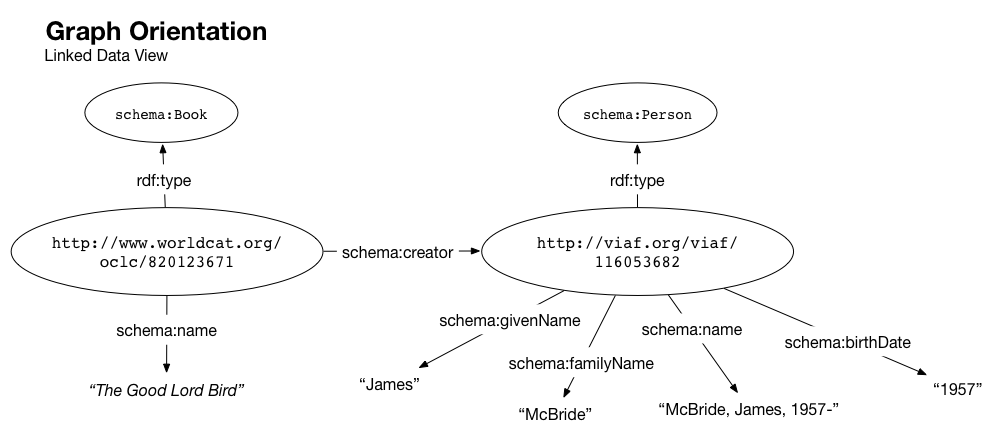
In this model, the entities are represented as ovals connected to various data properties through labeled arrows. Those properties connect to other entities or to literals like string values. In this version, the data serializes a little bit differently:
{
"@context": {
"rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"schema": "http://schema.org/"
},
"@id": "http://www.worldcat.org/oclc/820123671",
"@type": "schema:Book",
"schema:creator": {
"@id": "http://viaf.org/viaf/116053682",
"@type": "schema:Person",
"schema:birthDate": "1957",
"schema:familyName": "McBride",
"schema:givenName": "James",
"schema:name": "McBride, James, 1957-"
},
"schema:name": "The Good Lord Bird"
}
This example employs the core standard used to encode Linked Data, the Resource Description Framework. In this case specifically, we are using a JSON for Linking Data RDF serialization.
There are a few things worth noting here that make the RDF version different from plain-old-JSON version above. The common theme is that the data in the RDF version is chock full of links.
Globally Unique Identifiers
For example, rather than simply use a numeric identifier that is local to OCLC and WorldCat, but which could collide with the same number used in a different context, the way we identify this book and its creator is through an ID built upon the domain name system. Consequently, the identification of each of these real-world entities is globally unique. This is one of the core benefits of Linked Data. Using an HTTP-based URI to identify a thing enables one to work with an entity in any context without identifier collisions.
Open World Model
It is important to mention the traditional database model is closed-world. What this means is that model assumes that all available data is included in the database and that the data has to fit a particular structure. In contrast, the Linked Data model is open-world and assumes that there is always more data available externally and that the graph may extend in ways that you didn’t expect. This open world model is based on the fact that there are many resolvable identifiers within Linked Data. Because of this, fewer assumptions can be rigidly made when writing code.. This both forces you to be creative with how you code and removes limits on how you view the data and what you can do with it.
Resolvable Identifiers
Notice that the creator of the book is identified using one of those globally unique identifiers based on a location within the Virtual International Authority File. In the WorldCat Discovery API context, the brief bibliographic description may be used to build a search result set and only a few data properties of the author are needed. However, by using the HTTP-based URI as an identifier, your application now has a link to a larger and broader set of information about the author accessible on the Web.
Your application can send a subsequent request to the VIAF identifier for James McBride. This enables the data equivalent of browsing the web, known as “following your nose,” the underlying linking pattern for Linked Data. By resolving the data available from VIAF in this example, the client is capable of retrieving data for
- Alternate forms of James McBride’s name so that it can be displayed in the language of choice
- Other creative works by James McBride to put this bibliographic resource in context
- The location for other data descriptions about James McBride from national libraries or even the machine-readable version of Wikipedia
Here at OCLC we’re actively developing and enhancing our suite of entities that will provide more connections to the web. As this occurs, these entities will be incorporated into the API and enhance and replace existing entities within the data. We are hoping though that your work with the WorldCat Discovery API will not be bound to the subset of information about bibliographic entities (books, journals, movies, people, organizations, etc.) that we know about. Our goal is to connect you to the broader World Wide Web and the rich data sets that are just a link away.
Working with Graphs
We will wrap up here by giving you a quick introduction to writing code to consume Linked Data. To begin, it is important to just review the core syntax of RDF and how data assertions are made using RDF.
RDF Statement: Basic Data Structure
The core data structure of graph-based RDF data:
subject predicate object .
is fundamental to writing code that works with Linked Data sets. This basic assertion made up of three parts:
- Subject: the thing a given assertion is about
- Predicate: the property being asserted about the subject
- Object: the value corresponding to the property
It forms the atomic unit of data required to make the smallest graph containing one assertion. The simplicity of this basic data structure is what allows for the flexibility to link data from multiple sources together without needing to merge data from different schemas or object structures.
Query-based Parsing
Using a traditional XML or JSON parser, when retrieving data from an API, the client will typically iterate over the node or object structure of the data serialization. In this model, the data from the API is a serial stream of bytes intended to be read from a starting point to an end point. However, notice in the diagram above that a graph is not necessarily designed to behave in the same manner as a traditional tree-based structure.
Working with RDF data is a little bit different. The pattern for parsing and working with RDF data uses a load, query and repeat pattern:
- Load an initial set of RDF statements into a graph
- Query the graph for individual RDF statements (data assertions) using a combination of subject, predicate, object values
- Repeat from step 1 if more data needs to be loaded
Working with RDF data and web-accessible graphs utilizes a crawling pattern following data references until enough information is assembled to complete a task, such as displaying the relevant bibliographic entities for a book in a web page.
As pseudo code, it might look like the following:
// Assume this method makes a call to the API
data = lookupByOCLCNumber(820123671)
// Load the RDF data into a graph
graph = new Graph(data)
// Query the graph to retrieve the name of the thing identified by the first URI
// query() is assumed to take 3 parameters: a subject, a predicate, an object
graph.query("http://www.worldcat.org/oclc/820123671", "http://schema.org/name", null)
In working with the WorldCat Discovery API and putting it through its paces, our Developer Network team at OCLC has been writing code against the API using a couple of RDF libraries:
In our next post on this series, we will take a deeper look into how we have developed the WorldCat::Discovery Ruby gem to serve as a reference implementation for working with the WorldCat Discovery API.
The WorldCat Discovery API is currently available as a beta for a select number of libraries using WorldCat Discovery Services. Interested in participating in the beta? Contact us today.
-

Karen Coombs
Senior Product Analyst